
Siapa yang menggunakan Kode Claude? Jawabannya mungkin bukan programer
EMPAT RATUS RIBU SESI MENUNJUKKAN BAHWA AI TELAH MENURUNKAN AMBANG PEMROGRAMAN DAN MEMPERBESAR NILAI PENILAIAN LAPANGAN

Gelar asal: Badan bekerja dan hadir kembali ke ekspor
Foto oleh Antropoik
Foto oleh Peggy
Editor: Laporan ini didasarkan pada sekitar 400.000 sesi Claude Code membahas bagaimana alat pemrograman AI mengubah hubungan antara orang dan kode。
Intinya adalah bahwa, dalam pemrograman cerdas, manusia terutama bertekad untuk "melakukan apa," sementara Claude terutama bertanggung jawab untuk "melakukan apa". Pengguna borough mengambil sebagian besar keputusan perencanaan, sementara Claude mengambil sebagian besar implementasi. Artinya, AI mengambil alih pencapaian kode penulisan, mengubah dokumen, menjalankan perintah, debugging, dll, tetapi menargetkan dan penilaian hasil masih bergantung pada orang。
Yang lebih penting lagi, efek penggunaan Claude Code tidak hanya bergantung pada apakah penggunanya adalah programmer. Laporan tersebut menunjukkan bahwa dalam tugas pembuatan kode, tingkat keberhasilan pengguna pendudukan non-teknis, seperti legal, keuangan, manajerial dan ilmiah, dekat dengan para insinyur perangkat lunak. Apa yang benar-benar mempengaruhi hasil akhirnya adalah apakah pengguna memahami masalah yang akan mereka selesaikan。
INI BERARTI BAHWA PEMROGRAMAN AI MENURUNKAN AMBANG, BUKAN AMBANG PENILAIAN. PADA MASA DEPAN, MEREKA YANG MENGETAHUI BISNIS, TAHU ADEGAN, DAPAT MENGARTIKULASIKAN KEBUTUHAN DAN KEPUTUSAN HAKIM MUNGKIN LEBIH DAPAT MENGGUNAKAN AI DARIPADA MEREKA YANG HANYA MENULIS KODE. AI TIDAK SECARA OTOMATIS MENGGANTIKAN PENGETAHUAN DI LAPANGAN, TETAPI LEBIH MENINGKATKAN NILAINYA。
Berikut ini adalah teks asli:
Temuan kunci ilmiah
Atas dasar penelitian, kami telah mengusulkan kerangka untuk mempelajari pemrograman tubuh cerdas interaktif. Kerangka kerangka kerja didasarkan pada analisis perlindungan privasi sekitar 400.000 sesi Claude Code selama periode dari Oktober 2025 hingga April 2026, penilaian komposisi misi, bagaimana manusia berkolaborasi dengan AI, dan tingkat keberhasilan misi。
Pada sesi biasa, manusia bertanggung jawab atas keputusan yang paling direncanakan, misalnya keputusan tentang apa yang harus dilakukan; Claude bertanggung jawab atas sebagian besar keputusan eksekutif, misalnya keputusan tentang bagaimana melakukannya. Semakin besar keahlian pengguna ' s dalam bidang yang diberikan, semakin besar beban kerja setiap instruksi memicu Claude. Dalam penugasan coding, tingkat keberhasilan rata - rata kelompok pendudukan utama — misalnya, entah apa yang ingin dilakukan pengguna dan dengan bukti yang dapat diverifikasi seperti pengujian, kode penyerahan — hampir sama dengan yang dilakukan insinyur perangkat lunak。
Semakin besar keahlian di area pengguna, kemungkinan besar percakapan akan berakhir dengan sukses. Namun, kesenjangan antara pengguna perantara dan ahli tidak signifikan. Dalam tujuh bulan yang telah kita amati, proporsi sesi debug telah hampir terhalang, dan mode penggunaan telah bergeser ke penggunaan tubuh cerdas yang lebih akhir-ke-akhir: penyebaran dan menjalankan kode, analisis data, dan menulis dokumen non-kode。
Selama tujuh bulan ini, nilai misi khas meningkat di hampir semua jenis pekerjaan. Kami memperkirakan nilai misi dengan membandingkannya dengan informasi yang diterbitkan dalam pekerjaan bebas, menunjukkan peningkatan rata-rata sekitar 25 persen。
Pengantar Kata Pengantar
Pemrograman tubuh cerdas cepat meningkat. Sejak akhir tahun 2025, proporsi aktivitas kecerdasan pengkodean di GitHub memiliki lebih dari dua kali lipat, dan pengguna Claude Code sekarang menggunakan alat tersebut rata-rata 20 jam seminggu. Bisakah seseorang yang tidak memiliki pengalaman pemrograman formal berhasil mengarahkan tubuh cerdas untuk melakukan tugas teknis yang kompleks? Bagaimana adopsi dan peningkatan kapasitas alat - alat ini yang cepat akan mempengaruhi pekerjaan pengetahuan yang lebih luas? Kita belum bisa memberikan jawaban lengkap, tapi kita bisa melihat beberapa sinyal awal dari Claude Code。
Laporan ini memberikan bukti bagaimana Claude Code sebenarnya digunakan, berdasarkan analisis perlindungan privasi sekitar 235.000 pengguna dan sekitar 400.000 sesi interaktif antara Oktober 2025 dan April 2026. Ini mengikuti penelitian kita sebelumnya tentang indikator otonomi Claude Code, dan bagaimana Claude Code telah mengubah pekerjaan internal Antropik. Kertas ini akan menyajikan kerangka kerja untuk menjelaskan penggunaan asisten pemrograman AI interaktif: apa yang dilakukan orang, yang melakukan dan apakah mereka berhasil. Kami khawatir tentang penggunaan Claude Code oleh pengguna menggunakan antarmuka baris perintah (CLI), Claude.ai atau Claude Code aplikasi desktop. Dengan melacak bagaimana penggunaan pemrograman tubuh cerdas berubah seiring berkembangnya kemampuan model, kita dapat lebih memahami dampak alat-alat ini pada pasar tenaga kerja profesional programme dan pekerja pengetahuan。
Apa yang terjadi pada Claude Code mungkin merupakan tanda masa depan dari karya pengetahuan: Tubuh cerdas secara bertahap tertanam dalam pekerjaan non-pencoding. Kami menemukan bahwa Claude berurusan dengan tugas yang lebih kompleks dan berharga. Pada saat yang sama, masih ada pembagian kerja yang jelas dalam pemrograman tubuh cerdas: manusia memutuskan apa yang harus dibangun, dan tubuh cerdas memutuskan bagaimana membangun。
Kami juga telah melihat bukti bahwa alat penskalaan sebenarnya digunakan oleh keahlian lapangan daripada kemampuan pemrograman. Khususnya, para pakar di lapangan lebih cenderung berhasil dan pulih dari kesalahan dan kesalahpahaman. Namun, kesenjangan antara para ahli dan pengguna tingkat menengah tidak signifikan. Hal ini menunjukkan bahwa selama ada cukup proefisien di daerah yang diberikan, alat semacam itu dapat digunakan hampir sama efektifnya dengan spesialis kedalaman。
Temuan-temuan ini memungkinkan kita untuk melakukan pengamatan awal tentang kemungkinan perubahan di pasar buruh. Dalam data kita, kesuksesan bergantung pada apakah seseorang memahami masalah yang ingin ia selesaikan, bukan apakah ia telah dilatih dalam pemrograman. Jika model-model ini didirikan di seluruh sistem ekonomi, maka itu berarti bahwa alat pemrograman cerdas-tubuh, sementara mungkin menyerap beberapa pekerjaan berorientasi realisasi, juga memberi imbalan kepada mereka yang benar-benar memahami masalah yang mereka alamat dalam pekerjaan mereka. Kecerdasan pengekodan tidak terspesialisasi dalam bidang alternatif. Sebaliknya, semakin banyak pekerja membawa kepada yang cerdas, pekerjaan yang lebih berkualitas tinggi yang dapat dilakukan cerdas。
Divisi buruh
Apa yang orang lakukan dengan Claude Code
Untuk memahami bagaimana orang-orang menggunakan Claude Code, kita kelompokkan setiap sesi ke dalam salah satu dari sembilan model kerja, kegiatan tunggal yang terbaik menggambarkan tujuan sesi. Empat model ini berhubungan langsung dengan penulisan kode atau pemeliharaan: membangun hal-hal baru, memperbaiki hal-hal yang rusak, menguji kode, dan mengatur jalur air cerdas atau otomatis lainnya. Kategori lainnya adalah perangkat lunak operasi, termasuk penyebaran, konfigurasi, menjalankan jalur aliran dan sistem pemantauan. Ada dua jenis preferensi lebih untuk mengetahui apa yang harus dilakukan: Memahami bagaimana sistem yang ada bekerja dan merencanakan perubahan sebelum membuat perubahan. Dua kategori terakhir tidak terkait dengan kode, atau kode hanya merupakan bagian tambahan dari produk akhir: analisis data dan komunikasi melalui presentasi dan dokumen berbasis teks lainnya。
Diperkirakan 56 persen sesi terdiri dari penulisan kode (25 persen), perbaikan (26 persen) atau tes dan organisasi (5 persen persen). Perangkat lunak operasi berkapasitas 17 persen, perencanaan atau eksplorasi untuk 14 persen dan analisis atau penulisan untuk 13 persen (lihat angka 1)。
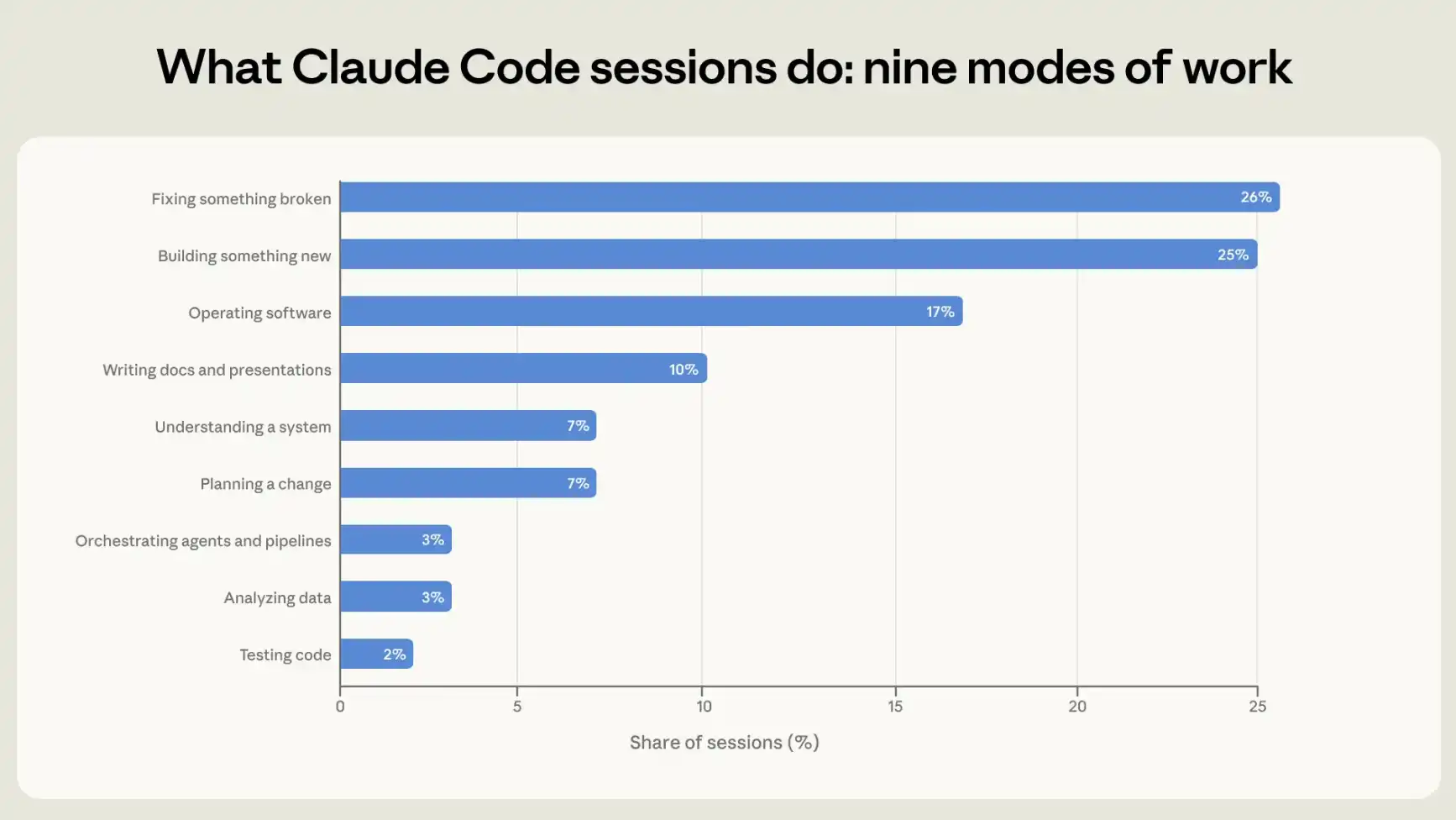
Gambar 1: 9 model kerja. Masing-masing sesi interaktif diklasifikasikan sebagai model kerja tunggal yang terbaik menggambarkan tujuannya。
Kami akan mengizinkan model untuk membaca catatan sesi dan mengklasifikasikan setiap sesi sesuai; kemudian kami akan menggunakan alat analisis perlindungan privasi kami untuk memeriksa silang hasil klasifikasi dengan data telemetri yang dicatat secara otomatis untuk setiap sesi, termasuk apakah baris kode telah ditambahkan atau dihapus. Ada tingkat konsistensi yang tinggi antara kedua sumber. Sebagai contoh, lebih dari 90% sesi di mana taksonomi kita ditandai untuk membuat atau memodifikasi kode juga menunjukkan perubahan kode dalam data telemetri. Apendiks untuk rinciannya。
Siapa yang membuat keputusan
Berapa kuatkah Kode Claude? Penilaian kapasitas menunjukkan bahwa langit - langit sudah tinggi dan masih naik. Sebagai contoh, dalam uji benchmarking seperti penilaian cakrawala waktu METR, model garis depan sekarang mampu melakukan tugas perangkat lunak yang akan membutuhkan beberapa jam usaha manusia dan untuk mengatasi hambatan dalam proses. Tapi dalam praktek, apa situasinya? Di sini, kita khawatir tentang berapa banyak bimbingan manusia dan Claude masing-masing memiliki。
Kita lihat ini dari dua sudut. Pertama, kita khawatir tentang sejauh mana orang-orang mengubah keputusan mereka ke Claude; kedua, kita melihat berapa banyak tindakan mereka telah ditugaskan ke Claude. Untuk memahami pembagian pengambilan keputusan dalam sesi, kami telah membangun subdivisi pengambilan keputusan untuk perlindungan privasi berdasarkan isi sesi. Kami meminta taksonomi untuk mencantumkan semua keputusan yang berarti dalam sesi dan membaginya ke dalam perencanaan dan keputusan implementasi. Keputusan perencanaan mengenai apa yang harus dilakukan, apa yang harus dilakukan, apa yang harus dilakukan; keputusan pelaksanaan mencakup dokumen mana yang harus dimodifikasi, kode apa yang harus ditulis, dalam bahasa mana, dan perintah mana yang harus dioperasikan. Secara berurutan, Katalog akan memberikan atribut setiap keputusan untuk Claude atau pengguna dan menghasilkan dua angka untuk setiap sesi: persentase keputusan perencanaan yang diambil oleh pengguna dan persentase keputusan implementasi yang diambil oleh pengguna。
Rata-rata, manusia membuat sekitar 70 persen keputusan perencanaan, tetapi hanya 20 persen keputusan implementasi (lihat angka 2). Dalam penggunaan praktis, pemrograman cerdas membentuk pembagian yang jelas dari tenaga kerja: manusia memutuskan apa yang harus dibangun, dan tubuh cerdas memutuskan bagaimana membangun。
Untuk memahami tingkat delegasi aksi dalam sesi, kita tidak melihat isi tetapi pada struktur sesi. Sesi Claude Code terdiri dari interaksi bulat-bulat antara Claude dan pengguna: pengguna mengirimkan petunjuk, Claude mengeksekusi tindakan; pengguna kemudian mengirimkan yang berikutnya, jadi. Pada sesi khas, rotasi seperti itu sekitar empat. Dalam data sejarah kami dari Oktober sampai April, setiap petunjuk yang dikirim oleh pengguna memicu Claude rata-rata sekitar 10 tindakan, kadang-kadang melebihi 100. Dalam setiap putaran, Claude akan membaca berkas, menyunting kode, menjalankan perintah dan mengeluarkan rata-rata 2400 kata。
Claude, berapa banyak pekerjaan yang dilakukan antara dua pemeriksaan pengguna tergantung pada besarnya siapa yang membuat keputusan. Ketika pengguna mempertahankan kontrol atas proses eksekusi, misalnya ketika pengguna membuat lebih dari 80% keputusan penegakan, Claude mengeksekusi lebih sedikit tindakan per putaran, sekitar 8. Dan ketika Claude mengambil alih perencanaan, Claude membuat lebih dari 80 persen keputusan perencanaan, itu melaksanakan jumlah tertinggi tindakan, sekitar 16。
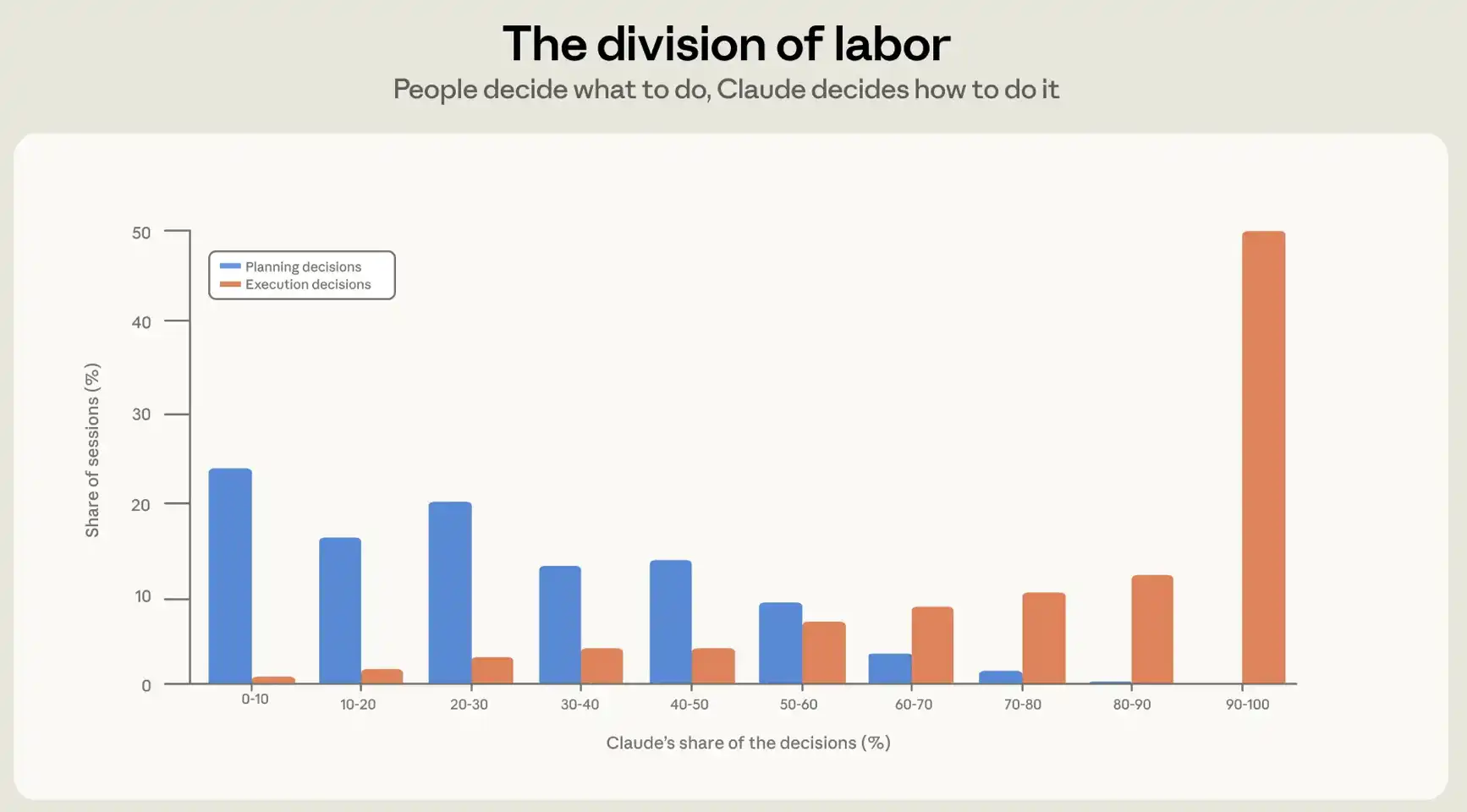
Figur 2: Claude ' s berbagi dalam perencanaan dan melaksanakan pengambilan keputusan. Tokoh tersebut menunjukkan bahwa dalam sesi yang berbeda, perencanaan pengambilan keputusan (apa yang harus dilakukan) dan pelaksanaan pengambilan keputusan (bagaimana melakukannya) adalah dapat dibagikan kepada Claude daripada distribusi persentase pengguna. Pada sesi tipikal, pengguna membuat sekitar 70% keputusan perencanaan, sementara Claude membuat sekitar 80% keputusan implementasi。
Level profesionalis
Menurut setiap catatan sesi, Claude menilai profesionalisme jelas pengguna pada tugas dalam skala lima tingkat, dari mahasiswa baru menjadi ahli. Klasifier level profesional dari FOTA berfokus pada tiga sinyal: keakuratan instruksi yang diberikan oleh pengguna, persyaratan pengguna bahwa Claude memverifikasi apa, dan apakah pengguna lebih sering mengoreksi Claude, atau Claude lebih sering. Perlu diperhatikan bahwa tingkat profesionalisme di sini benar-benar berbeda dari konsep post atau kompetensi umum, dan kuncinya adalah bahwa itu adalah misi-spesifik. Untuk pertama kalinya, seorang insinyur senior mengajukan pertanyaan tentang Rust, yang mungkin masih pemula dalam misi Rust. Seorang akuntan yang belum pernah menggunakan Python adalah ahli dalam tugas ini jika ia dapat secara akurat memberitahu Claude aturan rekonsiliasi apa yang harus diterapkan pada naskah Python dan mampu menangkap batas bahwa ia salah diproses pada akhir bulan。
Tabel di bawah ini menunjukkan bagaimana kita mendefinisikan tingkat spesialisasi di semua tingkatan dalam klasifikasi dan memberikan contoh permintaan dari data sesi tubuh cerdas yang terbuka yang ditetapkan SWE-chat. Dialog-dialog yang diklasifikasikan sebagai \"tangan baru\" memberikan instruksi umum yang tidak mencerminkan pengetahuan tentang bidang-bidang spesifik; dialog yang diklasifikasikan sebagai \"ahli\" menyampaikan pemahaman yang mendalam tentang perpustakaan kode dan lingkungan teknologi。
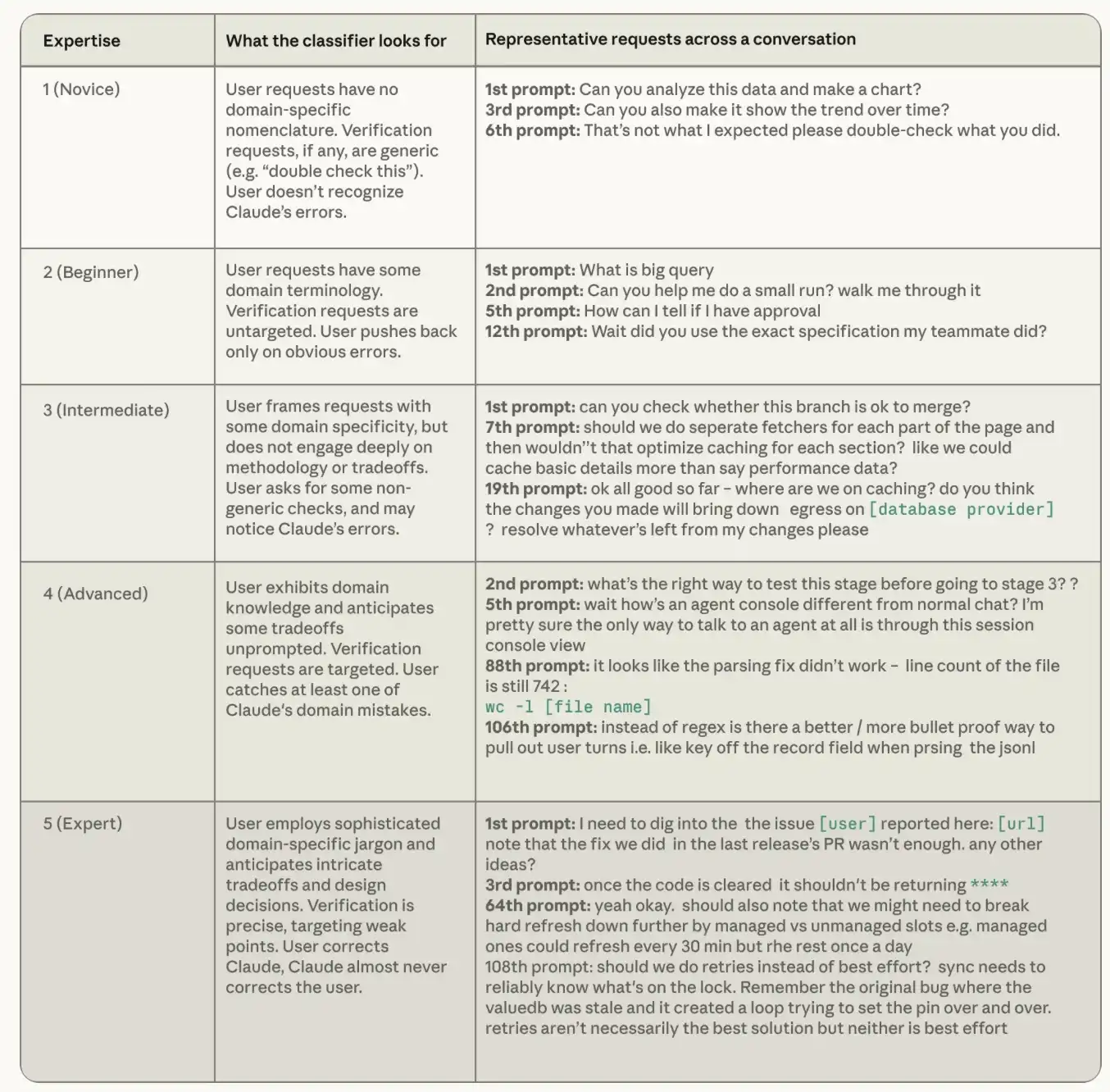
Klasifikasi Tingkat Profesional. Contoh: Sesi nyata ditulis ulang, secara anonim dan dimampatkan, dan sesi terkait ditandai oleh penyortir kami. Banyak dari contoh-contoh ini berasal dari sesi pemrograman tubuh cerdas terbuka dataset SWE-chat。
Kami telah mengukur hubungan antara tingkat keahlian dan output dan aktivitas yang dihasilkan oleh setiap petunjuk Claude. Pada sesi start-up khas, setiap petunjuk memicu Claude untuk mengeksekusi sekitar lima tindakan dan keluaran sekitar 600 kata; dalam sesi spesialis, panjang rantai aksi lebih dari dua kali lipat bekas, sekitar 12 tindakan, sementara volume keluaran mencapai sekitar 3200 kata, lima kali bekas (lihat angka 3). Kesenjangan antara pendatang baru dan ahli ini terjadi dalam setiap jenis pekerjaan dan setiap misi ' s zona nilai。
Indikator-indikator ini melengkapi penelitian kita sebelumnya tentang otonomi Claude Code. Penelitian-penelitian sebelumnya melacak panjang operasi tubuh cerdas dan frekuensi yang penggunanya menyetujui tindakan mereka secara otomatis. Secara kontras, indikator pengambilan keputusan kita menangkap siapa yang membuat keputusan substantif sepanjang sesi, sementara setiap petunjuk memicu output dan tindakan, mengukur sejauh mana setiap instruksi manusia memicu aktivitas otonom Claude。
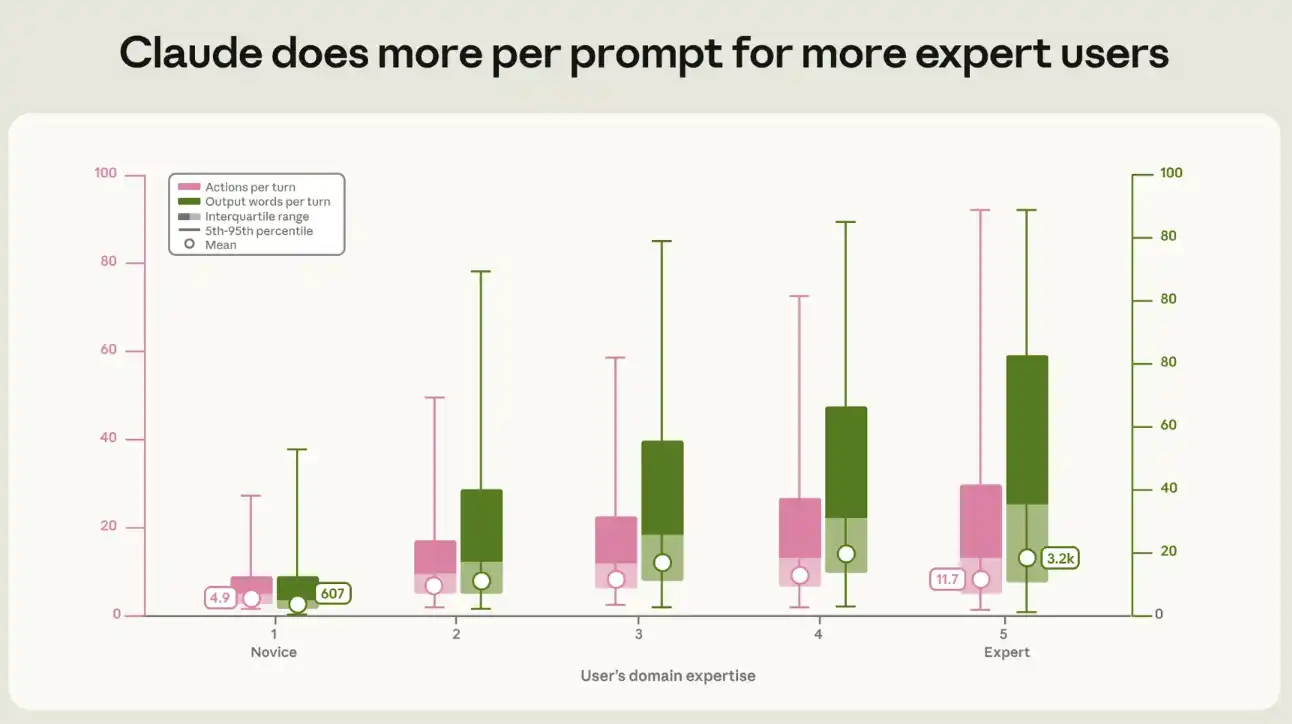
Untuk pengguna yang lebih profesional, Claude telah melakukan lebih banyak pekerjaan per petunjuk. Lebih tinggi tingkat profesionalisme, semakin banyak tindakan (kolum kiri) dan output teks (kolum kanan) yang dihasilkan oleh Claude per petunjuk. Kotak tersebut melambangkan kuadran dan dibagi dalam kisaran medium. Ditoggle menunjukkan 5 hingga 95 persen. Titik putih itu berarti geometris. Kedua tren ke atas secara statistik signifikan (p & lt; 0.001) dan perbedaan pada setiap langkah antara tingkat profesional tetangga secara statistik signifikan. Kecenderungan ini tetap signifikan setelah mengendalikan pola kerja, nilai misi, bulan, pendudukan dan seri model, dan mengikuti kesalahan oleh kriteria kelompok pengguna: jumlah aksi meningkat sebesar 9 persen dan output meningkat sebesar 13 persen untuk setiap langkah kemajuan profesional。
Siapa yang menggunakan Kode Claude, dan apa yang mereka lakukan dengan itu
Pengguna
DALAM RANGKA MEMAHAMI SIAPA YANG MELAKUKAN INI, KAMI MENGEKSTRADISI PENDUDUKAN SETIAP PENGGUNA DARI LOG SESI DAN MEMETAKANNYA KE SALAH SATU DARI 23 KATEGORI UTAMA DALAM UNITED STATES BUREAU OF LABOR STATISTICS STANDARD CLASSIFICATION OF OCCUPATIONS (SOC). KATALOGIS DIPERLUKAN UNTUK HANYA MENGADILI ATAS DASAR ISYARAT-ISYARAT BERIKUT: KONTEKS PROYEK, NAMA DAN STRUKTUR DOKUMEN, INFORMASI ATAU PRODUK YANG DIKUTIP PENGGUNA PADA AWAL SESI, SEPERTI DOKUMEN HUKUM, DATA KLINIS, LAPORAN KEUANGAN, BAHAN KURSUS, DLL, DAN TERMINOLOGI YANG DIGUNAKAN PENGGUNA. SORTER SECARA EKSPLISIT DIPERLUKAN UNTUK TIDAK MEMPERTIMBANGKAN "MENULIS KODE" SENDIRI SEBAGAI BUKTI PROFESI PEMROGRAMAN PENGGUNA. HANYA JIKA ADA SINYAL YANG JELAS BAHWA PERANGKAT LUNAK ATAU DATA BEKERJA ADALAH PEKERJAAN PENGGUNA, SESI TERSEBUT AKAN DIKLASIFIKASIKAN SEBAGAI KATEGORI KODE TERKAIT SOC, YAITU, "KOMPUTER DAN PROFESI MATEMATIKA". JIKA SEORANG PENGACARA MENYUSUN NASKAH UNTUK PEMERIKSAAN OTOMATIS TENTANG KETIADAAN ISTILAH TERTENTU DALAM SEKELOMPOK KONTRAK, BAHKAN JIKA SESI TERUTAMA TENTANG PERANGKAT LUNAK, AKAN DITEMPATKAN DALAM PROFESI HUKUM. JIKA TIDAK ADA SINYAL TENTANG PROFESI PENGGUNA, SESI TIDAK DIKLASIFIKASIKAN。
Kita bisa mengekstradisi karir sekitar 70% dari sesi. Tidaklah mengherankan bahwa \"profesi komputer dan matematika\" adalah kelompok terbesar dalam sesi-sesi rahasia ini, karena mencakup sebagian besar pekerjaan terkait perangkat lunak. Yang kedua adalah bisnis dan operasi keuangan, desain seni dan media, manajemen, dan ilmu kehidupan, ilmu fisik dan ilmu sosial. Dalam sampel kami, kelompok pendudukan non-perangkat lunak tercepat yang berkembang adalah manajemen, pemasaran dan legal。
Work
Dari Oktober 2025 hingga April 2026, ada perubahan yang ditandai dalam komposisi pekerjaan yang dilakukan menggunakan Claude Code. Perubahan yang paling menonjol adalah penurunan proporsi sesi yang digunakan untuk memperbaiki kode kerusakan dari 33 persen menjadi 19 persen (lihat angka 4). Sebaliknya, lebih bekerja di sekitar kode. persentase persentase perangkat lunak operasi meningkat dari 14% menjadi 21%. Penulisan dan analisis data hampir dua kali lipat, dari sekitar 10 persen menjadi sekitar 20 persen。
Nilai tugas itu sendiri juga sedang meningkat. Kita perkirakan nilai ekonomi setiap sesi dengan memperkirakan biaya dari jenis pekerjaan yang sama di pasar free-occupation dan mengkalibrasinya menggunakan set data real open job. Menurut indikator ini, perkiraan nilai sesi rata-rata meningkat sebesar 27 persen antara Oktober dan April. Peningkatan ini terjadi dalam berbagai jenis pekerjaan. Nilai dari build, mengoperasikan dan memperbaiki kategori meningkat sekitar 43 persen, 34 persen dan 32 persen, masing-masing. Perkiraan harga ini kasar, jadi kami menggunakannya terutama untuk membandingkan tren dari waktu ke waktu antara misi yang berbeda daripada sebagai nilai dolar yang dapat dibaca langsung. Detail tentang bagaimana perkiraan nilai misi dibangun dalam usus buntu。
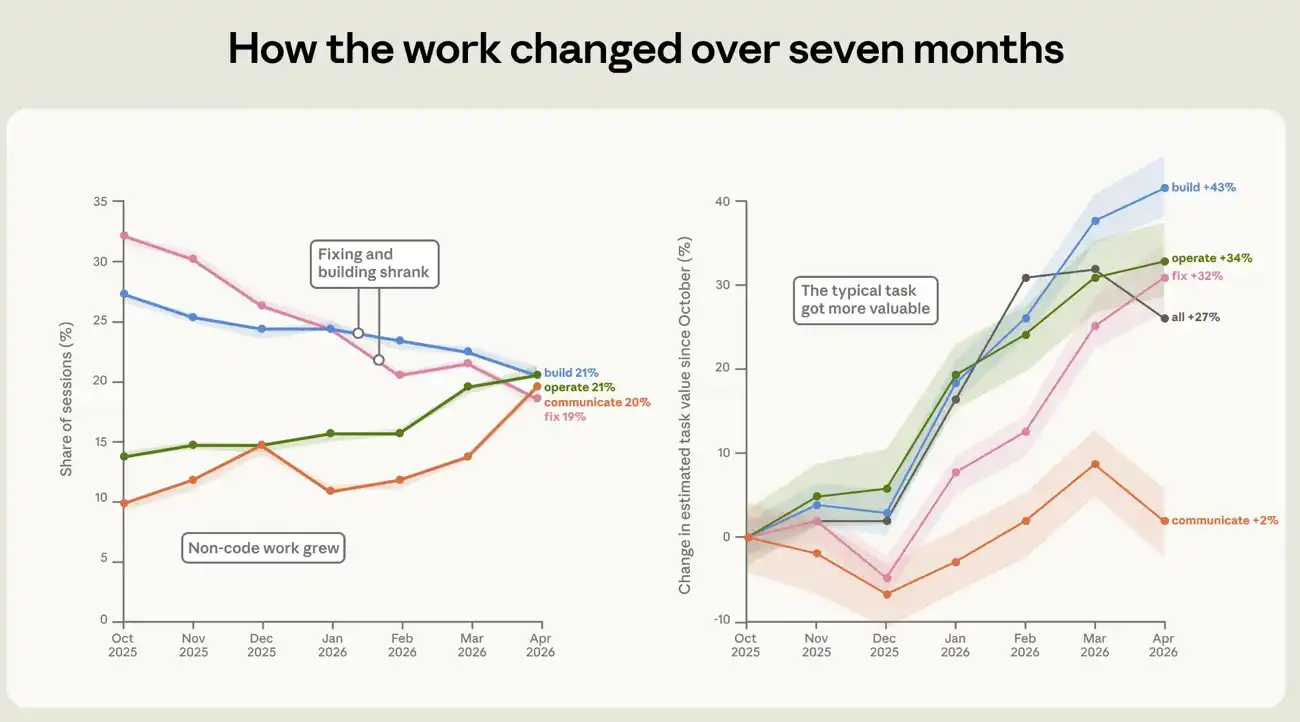
Gambar 4: Perubahan komposisi dan nilai Claude Code ' s bekerja dari Oktober 2025 sampai April 2026. Tabel ini menunjukkan proporsi pola kerja dalam sesi selama periode tujuh bulan jendela. Proporsi sesi untuk memperbaiki kode rusak menurun dari 33 persen menjadi 19 persen, sementara pembagian perangkat lunak operasi, data analitis dan penulisan dokumen meningkat。
Keberhasilan bergantung pada apa yang pengguna bawa
Menganggarkan nilai tugas adalah salah satu cara untuk memahami bagaimana Claude Code dapat membantu orang melakukan pekerjaan mereka. Perspektif lain adalah mengamati berapa banyak sesi yang telah berhasil dan karakteristik sesi mana yang relevan dengan keberhasilan. Di antara semua indikator keberhasilan, kita melihat pola yang jelas: semakin tinggi tingkat profesionalisme yang ditunjukkan oleh pengguna dalam sesi, semakin besar kemungkinan sukses. Sebagian besar upgrade terkonsentrasi di ujung bawah profesi, misalnya, kesenjangan antara start-up dan pengguna tingkat menengah lebih besar daripada kesenjangan antara pengguna tingkat menengah dan ahli。
Sebelum menganalisis karakteristik sesi sukses, kita perlu menyatakan dengan tepat bagaimana keberhasilan diukur. Kita tidak dapat mengamati hasil dunia nyata dari pengguna, dan juga tidak dapat kita tanyakan secara langsung apakah mereka melakukan apa yang mereka inginkan melalui Claude. Oleh karena itu, kami mengandalkan dua metode pengukuran pelengkap, berdasarkan catatan sesi. Yang pertama adalah "sukses" , di mana pengguna dinilai oleh apakah mereka telah mencapai tujuan yang dituju, termasuk sukses, keberhasilan parsial, kegagalan, dan kurangnya kejelasan. Selanjutnya, kedua juru katalog yang menyertainya akan menilai kekuatan yang jelas dari penilaian untuk menentukan \"kesuksesan eksperimental\". Pengklasifikasi sinyal yang sukses untuk mencari bukti sukses yang dapat diverifikasi, termasuk, khususnya, kegiatan guit yang sesuai dengan pekerjaan, seperti penyerahan dan permintaan tarik, jalur paket uji dan persetujuan pengguna eksplisit. Ia memberikan skor sesi sesuai dengan skala dari "no signal" ke "weak signal " (1 menit) ke "multiplier sinyal keras " (5 menit). Klasifikasi sinyal kegagalan paralel lainnya dari golongan sinyal paralel yang dinilai sebagai bukti kesalahan, termasuk kesalahan, gagal tes, percobaan berulang pada hal yang sama, dan keberatan pengguna terhadap output. Kedua kondisi diperlukan untuk keberhasilan yang terbukti: sesi dinilai sukses dan setidaknya ada satu tanda sukses yang dapat diverifikasi secara keras. Analisis berikut ini berfokus pada tingkat keberhasilan atau kegagalan dalam sesi, jadi kita mengecualikan mereka yang telah diidentifikasi oleh penggolongan hasil yang sukses sebagai "objek yang tidak didefinisikan " , yang kira-kira 7,7 persen dari total sampel。
Kembalian profesional
Jadi, sesi mana yang paling mudah untuk berhasil? Hasil tersebut menunjukkan bahwa peringkat profesional di atas yang disebutkan dari sesi tersebut memiliki dampak signifikan pada keberhasilannya。
Mungkin ada kekhawatiran bahwa profesionalisme bukanlah pengemudi yang sebenarnya. Mungkin para ahli memilih mandat yang berbeda atau ada perbedaan di daerah lain. Di bagian ini, kita sebagian menanggapi kekhawatiran ini dengan membandingkan jenis pekerjaan yang sama, nilai perkiraan yang sama, bulan yang sama, materi subjek yang sama, dan percakapan dari kelompok pendudukan luas yang sama, dan melihat bagaimana tingkat profesional pengguna yang berbeda dapat mempengaruhi hasil。
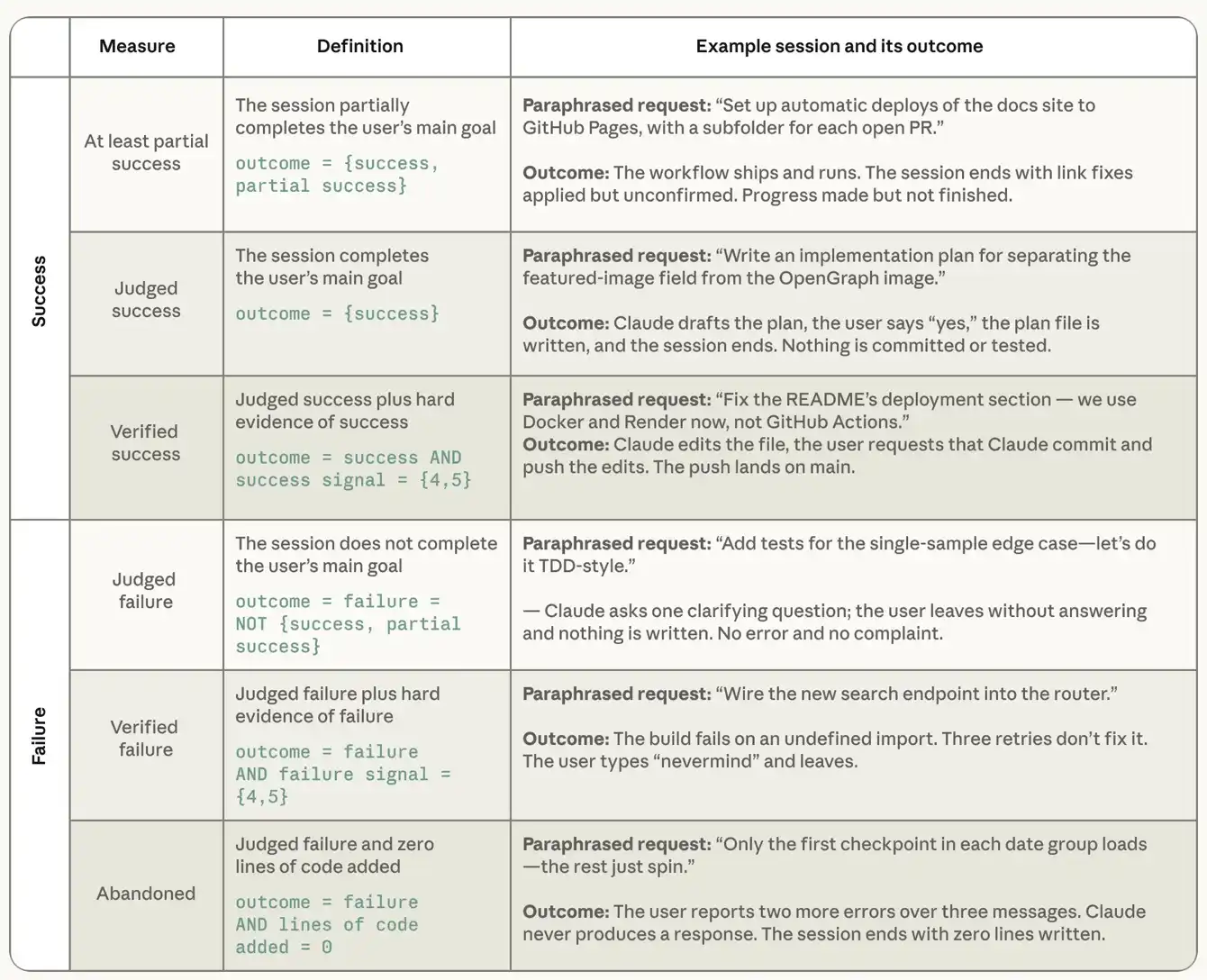
Tabel 2: Definisi keberhasilan dan kegagalan yang berasal dari klasifikasi. Contoh tersebut berasal dari sesi nyata dalam dataset interaktif pemrograman tubuh cerdas terbuka SWE-chat, yang ditandai dengan taksonomi kita setelah ditulis ulang dan dirangkum。
Dari semua indikator kesuksesan, semakin tinggi tingkat profesionalisme yang ditunjukkan oleh pengguna dalam sesi, semakin besar kemungkinan sesi akan berhasil. Tingkat keberhasilan untuk sesi yang baru dinilai adalah 15 persen untuk indikator terkuat kita dari "kemampuan sukses",dan 77 persen untuk setidaknya sebagian dari itu. Pertemuan-pertemuan yang dinilai sebagai tingkat pertengahan dan di atas dialami dari 28 hingga 33 persen, dengan keberhasilan sebagian berkisar antara 91 hingga 92 persen (lihat angka 5)。
Untuk setiap indikator, mayoritas keuntungan adalah dari peningkatan dari awal ke tengah; dari tengah ke ahli, kemiringan lambat. Apendiks untuk rincian analisis regresi di belakang angka 5。
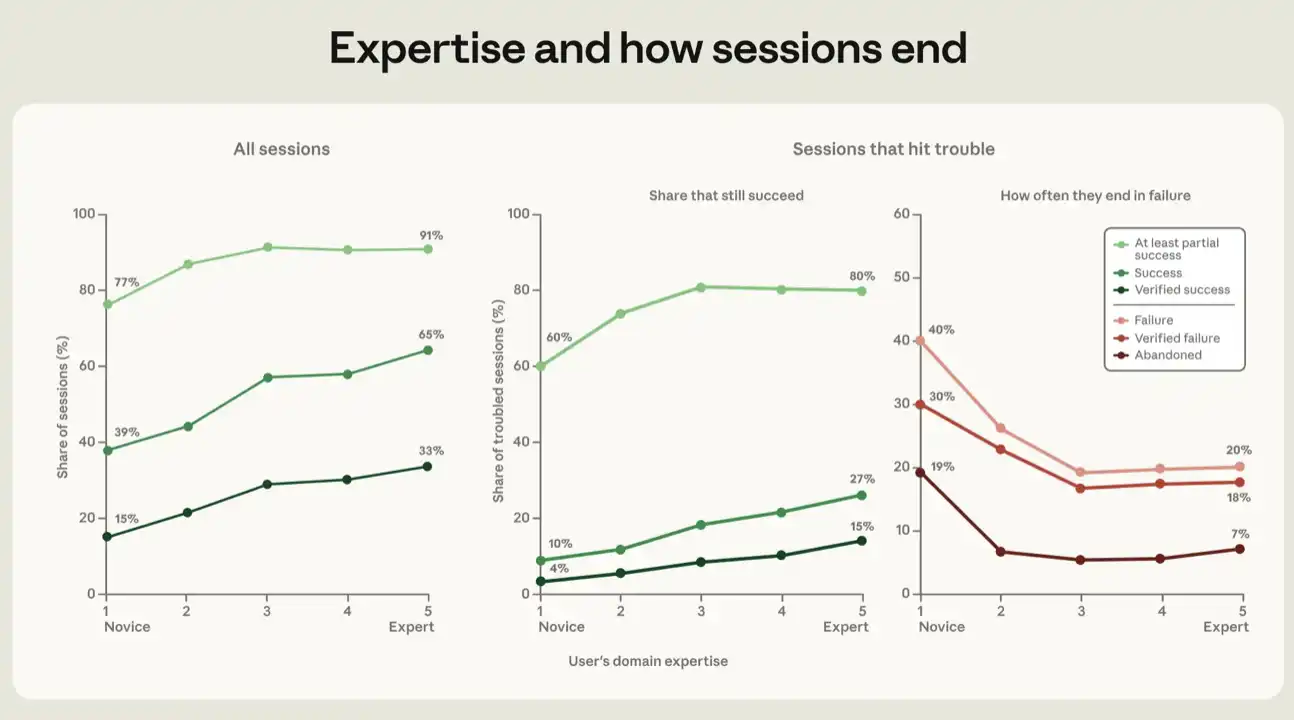
Gambar 5: Hasil partisipasi profesional. chart menunjukkan hasil sesi dalam lima nilai, dari mahasiswa baru menjadi ahli, menurut tingkat profesional pengguna dalam misi. Bagan kiri berisi semua sesi. Bagan tengah dan kanan terbatas pada sesi di mana masalah dihadapi, misalnya di mana sinyal kegagalan lebih besar dari 3 dan menunjukkan bagaimana sesi ini akhirnya mencapai proporsi yang berbeda dari keberhasilan dan kegagalan. Setiap titik adalah rasio yang disesuaikan. Kami memperkirakan perbedaan antara tingkat profesional dengan membandingkan hanya sesi dengan model kerja yang sama, kisaran nilai misi yang sama, bulan yang sama, tema misi yang sama, dan tipe pengguna yang sama, misalnya, apakah atau tidak mereka termasuk ke dalam pendudukan terkait perangkat lunak. Rincian dari pengembalian yang relevan disediakan dalam usus buntu. Kabel adalah zona kepercayaan dari rata-rata sampel, yang sebagian besar tidak terlihat karena kekecilan mereka. Angka-angka angka ini mengecualikan sesi yang telah diidentifikasi oleh penggolongan hasil yang sukses sebagai "tujuan yang tidak ditentukan"。
Gradien serupa dapat diamati pada sesi tantangan. Ketika sinyal kegagalan dicatat dalam bukti empiris kegagalan, kami pikir sesi ini "bermasalah." Ini mungkin termasuk kesalahan, kegagalan tes, berbagai upaya untuk menyelesaikan hal yang sama, atau ekspresi frustrasi dan ketidakpuasan oleh pengguna. Saat semua variabel di atas dikendalikan, persentase keberhasilan yang dialami meningkat dari 4 persen sesi pertama menjadi 15 persen sesi ahli (lihat angka 5). Jika indikator sukses liberal lebih banyak digunakan, kita menemukan setidaknya tingkat keberhasilan parsial 60 persen di antara pengguna start-up dan 80 hingga 81 persen di antara pengguna tingkat menengah ke tingkat ahli。
Kami juga telah melacak hubungan terbalik lainnya, hubungan antara profesionalisme dan berbagai indikator kegagalan. Perlu dicatat bahwa, dalam analisis ini, sesi yang telah dihukum gagal adalah sesi yang bahkan belum berhasil sebagian. Jika sesi dengan masalah dinilai gagal dan tidak ditulis dalam garis kode apapun, kita menyebutnya ditinggalkan. Dari sesi di mana pengguna tampaknya rookie, 19% akhirnya ditinggalkan; dalam kelompok pengguna lain, proporsinya antara 5% dan 7%. Dengan kata lain, pengguna dengan sedikit pengalaman lebih cenderung menyerah ketika mereka berjuang untuk mencapai tujuan mereka. Diatas dari nilai kompetensi profesional tampaknya kemampuan untuk mengarahkan intelijen kembali ke arah yang benar。
Karier mungkin kurang penting daripada kualifikasi profesional
Tingkat keberhasilan empiris untuk pengguna pendudukan terkait perangkat lunak dalam semua sesi adalah sekitar 30 persen dan untuk pengguna pendudukan lainnya sekitar 26 persen. Pada sesi generasi, di mana setidaknya satu baris kode ditambahkan atau dimodifikasi, angkanya 34 persen dan 29 persen, masing-masing (lihat angka 6). Jika definisi sukses yang lebih liberal digunakan, kesenjangan antara pendudukan terkait perangkat lunak dan pendudukan lainnya akan dipersempit lebih lanjut. Pada sesi generasi, dua kategori pengguna mencapai setidaknya tingkat keberhasilan parsial sebesar 89 persen dan 88 persen, masing-masing. Perbedaan perbedaan lima poin persentase tidak signifikan dan tidak diperlebar atau dipersempit dalam tujuh bulan, meskipun tingkat keberhasilan telah meningkat di kedua kelompok. Pada sesi generasi, masing-masing dari 10 kelompok penduduk terbesar dalam set data kami adalah dalam tujuh persentase poin keberhasilan. Kependudukan tipe manajemen bertipe manajemen memiliki tingkat keberhasilan yang terbukti paling tinggi, sedikit lebih tinggi daripada kependudukan tipe rekayasa perangkat lunak. Tingkat keberhasilan empiris yang lebih tinggi bagi manajer mungkin mencerminkan kemampuan keterampilan manajemen untuk bermigrasi ke tugas komando intelijen. Namun ini bisa sebagian dari pengukuran kita: Validasi bergantung pada beberapa tingkat konfirmasi eksplisit oleh pengguna sesi, dan manajer mungkin lebih terbiasa mengekspresikan diri ketika mereka mendapatkan hasil yang mereka inginkan。
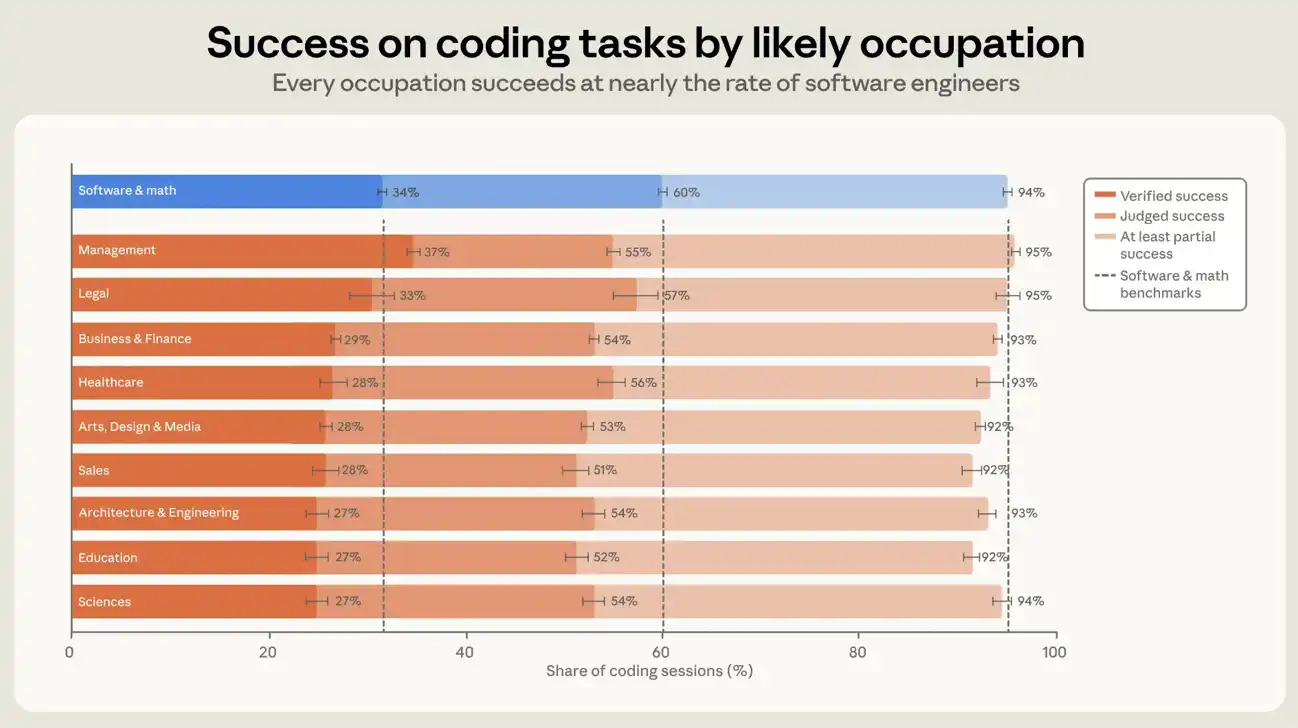
FIGURE 6: SESI PENGEKODAN DENGAN MENYIMPULKAN PENDUDUKAN MENENTUKAN TINGKAT KEBERHASILAN DAN TINGKAT KEBERHASILAN EMPIRIS. TABEL BAHASAN MENUNJUKKAN DEFINISI TINGKAT KEBERHASILAN YANG KETAT OLEH EKSTRAPOLASI PENGGUNA KLASIFIKASI PENDUDUKAN DALAM SESI DI MANA SETIDAKNYA SATU BARIS KODE TELAH DITAMBAHKAN ATAU DIMODIFIKASI, TERMASUK PENENTUAN KEBERHASILAN DAN PENGALAMAN. TOKOH TERSEBUT MENUNJUKKAN 10 KELOMPOK PENDUDUKAN TERBESAR. PERBEDAAN TINGKAT KEBERHASILAN ANTARA MASING-MASING KELOMPOK DAN PENGGUNA PERANGKAT LUNAK/MATEMATIKAL, MISALNYA PENGGUNA PROFESIONAL KOMPUTER DAN MATEMATIKA DALAM KLASIFIKASI SOC, BERADA DALAM TUJUH PERSENTASE POIN. GARIS KESALAHAN MEWAKILI 95 PERSEN INTERVAL KEYAKINAN BERDASARKAN AKUN YANG BERBEDA。
MASUK
Hasil laporan ini menguraikan gambaran yang muncul: Pemrograman tubuh cerdas memperluas beberapa pengetahuan dan keterampilan sambil menggantikan orang lain. Tingkat keberhasilan dari pendudukan besar dalam sesi generasi tidak berbeda secara signifikan dari pendudukan terkait perangkat lunak. Tampaknya bahwa kecerdasan mengkode membuat latar belakang pemrograman kurang penting untuk pemrograman sukses。
Pada waktu yang sama, sesi sukses lebih mungkin menunjukkan keahlian lapangan. Sesi ahlinya dinilai lebih dari dua kali lebih sukses daripada sesi yang lebih baru. Ketika sesi bermasalah, jumlah pendatang baru yang menyerah juga beberapa kali lebih tinggi daripada bagi pengguna lain. Pendekatan kolaboratif itu sendiri membuat gambaran ini lebih jelas: para ahli lapangan dapat mengarahkan Claude untuk melakukan lebih banyak dengan setiap arahan. Dengan demikian, kemampuan untuk memimpin Claude sukses lebih banyak berasal dari kemampuan menguasai suatu daerah daripada kemampuan menulis kode. Kini, bagi siapa pun yang memiliki penguasaan seperti itu dalam bidang apa pun untuk menyelesaikan pekerjaan teknis yang sebelumnya mustahil. Mereka yang tidak memiliki pemahaman profesional ini, misalnya menggunakan alat yang sama, akan memiliki jauh lebih sedikit untuk mendapatkan. Selain itu, manfaat yang diperoleh terutama dari kompetensi bukan keunggulan. Dengan pemahaman operasional daerah tertentu, sebagian besar manfaat telah dicapai; atas dasar ini, spesialisasi mendalam hanya akan memberikan keuntungan tambahan yang kecil。
Temuan ini masih awal. Seperti sebagian besar penelitian kita, kita tidak dapat mengukur hasil dunia nyata, seperti apakah kode yang ditulis dalam sesi kemudian digunakan atau dibuang, atau apakah itu menghasilkan hasil yang bernilai ekonomi. Selain itu, penggunaan non-interaktif yang dikecualikan dari laporan ini mewakili proporsi signifikan dari aktivitas keseluruhan. Pengembangan kerangka kerja untuk mengukur penggunaan tersebut merupakan salah satu prioritas untuk pekerjaan di masa depan. Selain itu, seluruh kategori sesi bergantung pada model pembacaan catatan sesi. Di dalam apendiks, kita menunjukkan bahwa sorter konsisten dengan arah yang dimaksudkan dari data telemetri independen dan dengan penilaian model referensi yang kuat dalam kebanyakan sesi. Namun, dalam skenario skala besar, tetap sulit untuk memverifikasi klasifikasi; sesi Claude Code sendiri lebih sulit karena mereka mungkin terlalu panjang dan terlalu kompleks untuk menggunakan pelabelan manual sebagai tanda aras nyata。
Model, pengguna dan pembagian tenaga kerja di antaranya berevolusi, gambar dalam laporan saat ini juga akan terus diperbarui. Kami berharap bahwa indikator ini akan membantu kami melacak transformasi besar yang sedang terjadi. Sebagai contoh, jika pengembalian dari tingkat profesional di masa depan mulai menurun, ini akan menunjukkan bahwa model mulai memberikan penilaian kritis yang sekarang dibawa oleh pengguna dan bahwa manfaat dari alat-alat ini juga akan diperpanjang dari ahli lapangan ke khalayak yang lebih luas. Jika proporsi sesi coding sukses oleh pengguna di luar profesi perangkat lunak terus meningkat, itu mungkin berarti bahwa produksi perangkat lunak menjadi bagian dari pekerjaan biasa di berbagai bidang daripada produk dari pendudukan tunggal. Perubahan ini akan mengubah siapa yang dapat memperoleh manfaat dari pemrograman tubuh cerdas, dan seberapa banyak mereka akan memperoleh keuntungan, dan memiliki dampak pada kapasitas yang paling dihargai di pasar tenaga kerja。
[Terkekeh]Bahasa Asli]
