
Who used Claude Code? The answer may not be a programmer
FOUR HUNDRED THOUSAND SESSIONS SHOW THAT AI HAS LOWERED THE PROGRAMMING THRESHOLD AND MAGNIFIED THE VALUE OF FIELD JUDGEMENT

Original title: Agency working and present returns to export
Photo by Anthropoic
Photo by Peggy
Editor: This report is based on about 400,000 Claude Code sessions discussing how the AI programming tool is changing the relationship between people and codes。
The central point of the article is that, in the intelligent programming, humans are primarily determined to "do what," while Claude is primarily responsible for "do what". Users take most planning decisions, while Claude takes most implementation. That is to say, AI is taking over the achievement of writing codes, changing documents, running orders, debugging, etc., but targeting and outcome judgement are still dependent on people。
More importantly, the effect of using Claude Code does not depend solely on whether the user is a programmer. The report shows that in the task of creating codes, the success rate of non-technical occupational users, such as legal, financial, managerial and scientific, is close to that of software engineers. What really affected the outcome was whether the users understood the problems they were about to solve。
THIS MEANS THAT AI PROGRAMMING LOWERS THE THRESHOLD, NOT THE THRESHOLD OF JUDGEMENT. IN THE FUTURE, THOSE WHO KNOW BUSINESS, KNOW SCENES, CAN ARTICULATE NEEDS AND JUDGE OUTCOMES MAY BE BETTER ABLE TO USE AI THAN THOSE WHO SIMPLY WRITE CODES. AI DOES NOT AUTOMATICALLY REPLACE KNOWLEDGE IN THE FIELD, BUT RATHER ENHANCES ITS VALUE。
The following is the original text:
Key findings
On the basis of established research, we have proposed a framework for studying the programming of interactive intelligent bodies. The framework is based on a privacy protection analysis of approximately 400,000 Claude Code sessions during the period from October 2025 to April 2026, an assessment of the composition of the mission, how humans collaborate with AI, and the success rate of the mission。
In a typical session, humans are responsible for most planning decisions, i.e. decisions on what to do; Claude is responsible for most executive decisions, i.e. decisions on how to do it. The greater the user ' s expertise in a given field, the greater the workload each instruction triggers Claude. In coding assignments, the average success rate of the main occupational groups — i.e., whether or not what the user would have wanted to do and with verifiable evidence such as testing, submission codes — is almost the same as that of software engineers。
The greater the expertise in the user area, the more likely the conversation will end successfully. However, the gap between intermediate and expert users is not significant. In the seven months we have observed, the proportion of debugging sessions has almost halved, and the mode of use has shifted to more end-to-end smart body usage: deployment and running codes, data analysis, and writing non-code documents。
During these seven months, the value of typical missions rose in almost all job types. We estimate the value of the mission by comparing it with the information published in the free jobs, showing an average increase of about 25 per cent。
Introduction
Smart body programming is rapidly rising. Since the end of 2025, the proportion of coding intelligence activity in GitHub has more than doubled, and Claude Code users now use the tool on average 20 hours a week. Can a person with no formal programming experience successfully direct an intelligent body to perform complex technical tasks? How will the rapid adoption and capacity enhancement of these tools affect broader knowledge work? We can't give a complete answer yet, but we can see some early signals from Claude Code。
This report provides evidence of how Claude Code was actually used, based on a privacy protection analysis of approximately 235,000 users and about 400,000 interactive sessions between October 2025 and April 2026. It follows our previous research on the autonomy indicators of Claude Code, and how Claude Code has changed the internal work of Anthropic. This paper will present a framework for describing the use of interactive AI programming assistants: what people do, who does and whether they succeed. We are concerned about the use of Claude Code by users using command line interfaces (CLI), Claude.ai or Claude Code desktop applications. By tracking how the use of smart body programming changes as model capabilities grow, we can better understand the impact of these tools on the labour market of programme professionals and knowledge workers。
What happens on Claude Code may be a sign of the future of knowledge work: intelligent bodies are gradually embedded in non-coding jobs. We found that Claude was dealing with more complex and valuable tasks. At the same time, there is still a clear division of labour in the programming of intelligent bodies: human beings decide what to build, and intelligent bodies decide how to build。
We have also seen evidence that the real scaling-up tool is used by field expertise rather than programming proficiency. In particular, experts in the field are more likely to succeed and recover from mistakes and misunderstandings. However, the gap between experts and mid-level users is not significant. This suggests that as long as there is sufficient proficiency in a given area, such tools can be used almost as effectively as depth specialists。
These findings allow us to make preliminary observations of possible changes in the labour market. In our data, success depends on whether a person understands the problems he or she wants to solve, not whether he or she has been trained in programming. If these models are established throughout the economic system, then it means that smart-body programming tools, while possibly absorbing some of the realization-oriented work, also reward those who truly understand the problems that they address in their work. Encoding intelligence is not specialized in alternative areas. On the contrary, the more a worker brings to the intelligent, the more high-quality work the intelligent can perform。
Division of labour
What do people do with Claude Code
In order to understand how people use Claude Code, we group each session into one of nine working models, the single activity that best describes the session's objectives. Four of these models relate directly to code writing or maintenance: building new things, repairing damaged things, testing codes, and arranging other intelligent or automated water lines. The other category is operating software, including deployment, configuration, running flow lines and monitoring systems. There are two more types of preference for knowing what to do: understanding how an existing system works and planning changes before making changes. The last two categories are not related to codes, or codes are only auxiliary parts of the end product: analysis of data and communication through presentations and other text-based documents。
Approximately 56 per cent of the sessions consisted of code writing (25 per cent), repair (26 per cent) or test and organization (5 per cent). Operating software accounts for 17 per cent, planning or exploration for 14 per cent and analysis or writing for 13 per cent (see figure 1)。
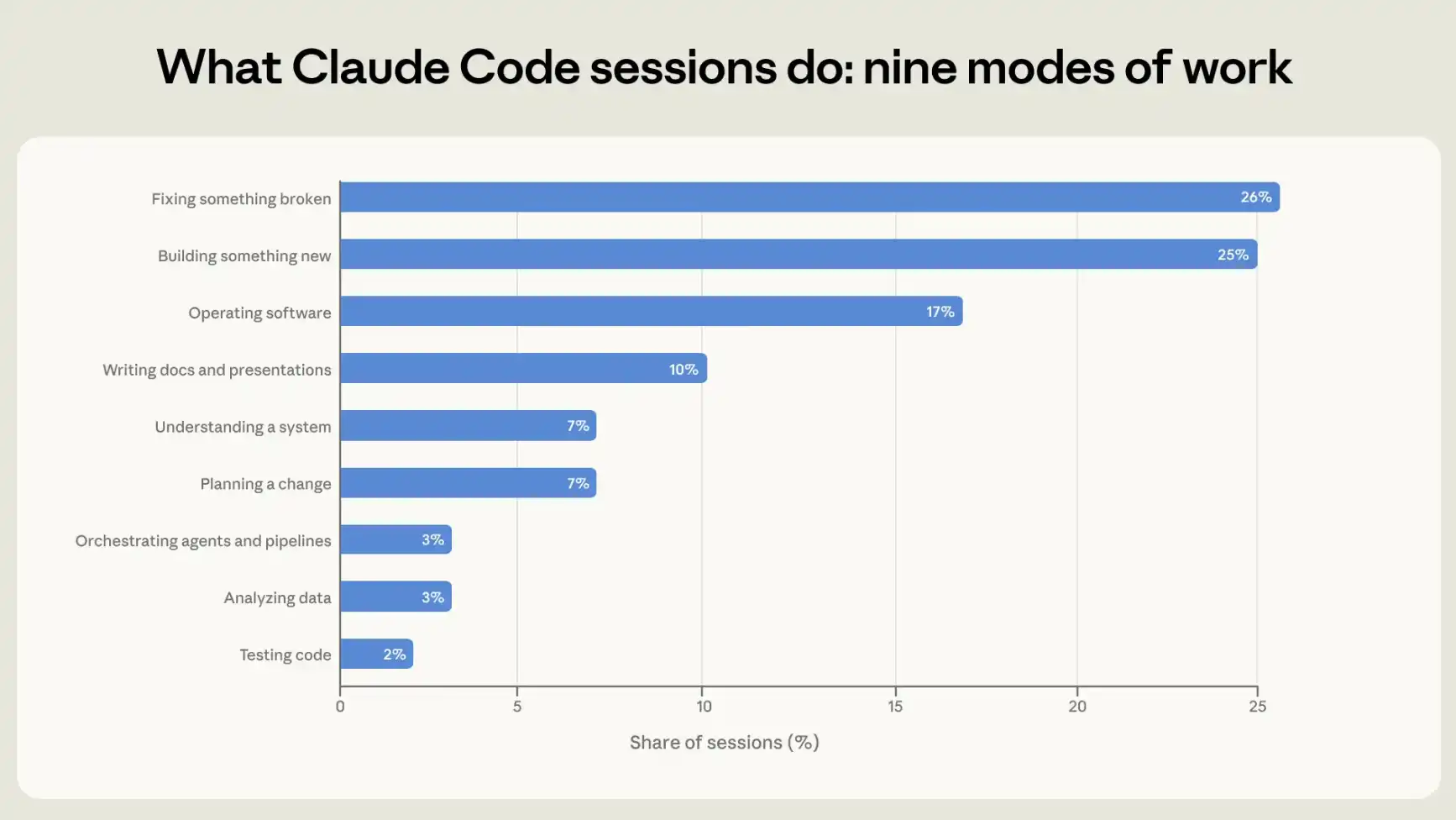
Figure 1: Nine working models. Each interactive session is classified as a single working model that best describes its objectives。
We will allow the model to read the session records and classify each session accordingly; then we will use our privacy protection analysis tool to cross-check the classification results with the telemetry data recorded automatically for each session, including whether code lines have been added or deleted. There is a high degree of consistency between the two sources. For example, over 90% of the sessions where our taxonomy is marked to create or modify codes also show code changes in telemetry data. See appendix for details。
Who makes the decision
How powerful is Claude Code? The capacity assessment showed that the ceiling was already high and was still rising. For example, in benchmarking tests such as the METR time horizon assessment, front-line models are now able to perform software tasks that would have required several hours of human effort and to overcome obstacles in the process. But in practice, what is the situation? Here, we're concerned about how much guidance humans and Claude each have。
We look at this from two angles. First, we're concerned about the extent to which people turn their decisions over to Claude; second, we're looking at how much action they have assigned to Claude. In order to understand the division of decision-making in a session, we have constructed a decision-making subdivision for privacy protection based on the content of the session. We ask the taxonomy to list all meaningful decisions in the sessions and to divide them into planning and implementation decisions. Planning decisions include what is to be done, what is to be done, what is to be done; implementation decisions include which documents are to be modified, what codes are to be written, in which languages, and which orders are to be operated. Subsequently, the Catalogue will attribute each decision to Claude or the user and generate two figures for each session: the percentage of planning decisions taken by the user and the percentage of implementation decisions taken by the user。
On average, humans make about 70 per cent of planning decisions, but only 20 per cent of implementation decisions (see figure 2). In practical use, intelligent programming forms a clear division of labour: human beings decide what to build, and intelligent bodies decide how to build。
In order to understand the degree of delegation of action in a session, we do not look at content but at the structure of the session. Claude Code session consists of a round-and-round interaction between Claude and the user: the user sends a hint, Claude executes an action; the user then sends the next one, so. In typical sessions, such rotations are about four. In our historical data from October to April, each hint sent by a user triggers Claude on average about 10 actions, sometimes exceeding 100. In each round, Claude will read files, edit codes, run commands and output an average of 2400 words。
Claude, how much work is done between two user checks depends to a large extent on who is making decisions. When the user retains control over the execution process, i.e. when the user makes more than 80% enforcement decisions, Claude executes fewer actions per round, about 8. And when Claude took control of planning, Claude made more than 80 percent of planning decisions, it carried out the highest number of actions, about 16。
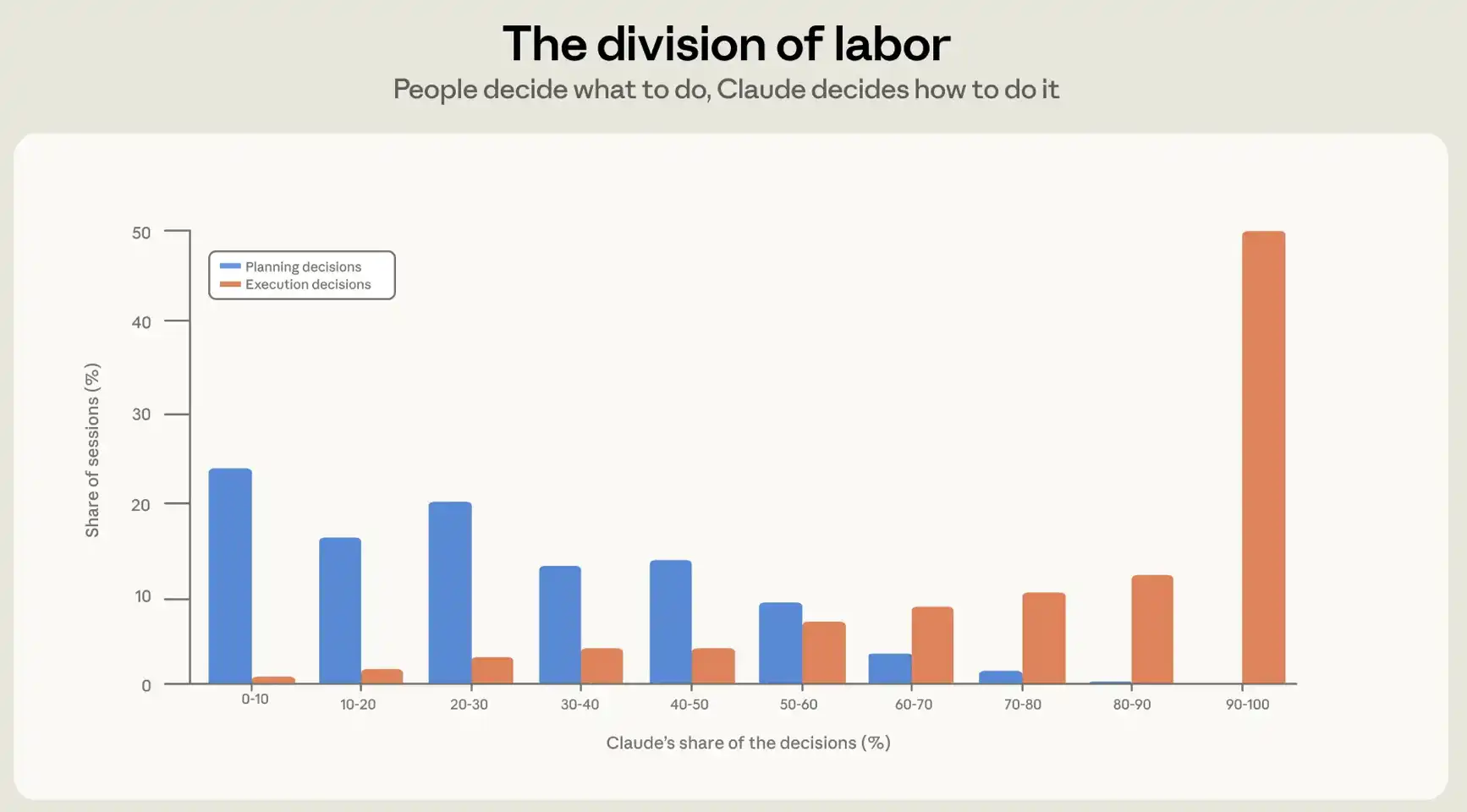
Figure 2: Claude ' s share in planning and implementing decision-making. The figure shows that in the different sessions, planning decision-making (what to do) and implementation decision-making (how to do it) is attributable to Claude rather than to the distribution of the percentage of users. In typical sessions, users make about 70% planning decisions, while Claude makes about 80% implementation decisions。
Professional level
According to each session record, Claude assesses the user's apparent professionalism on the task in a five-level scale, from freshman to expert. The professional level classifier focuses on three signals: the accuracy of the instructions given by the user, the user's requirement that Claude verify what, and whether the user corrects Claude more often, or Claude more often. It is important to note that the level of professionalism here is completely different from the concept of a post or general competence, and the key is that it is mission-specific. For the first time, a senior engineer asked questions about Rust, which may still be a beginner on the Rust mission. An accountant who has never used Python is an expert in this task if he can accurately tell Claude what reconciliation rules must be applied to a Python script and be able to capture the boundary that he misprocessed at the end of the month。
The table below shows how we define the level of specialization at all levels in the classification and gives an example request from the open coded smart body session data set SWE-chat. Dialogues classified as “new hands” give general instructions that do not reflect knowledge of specific areas; dialogues classified as “experts” convey an in-depth understanding of the code library and the technological environment。
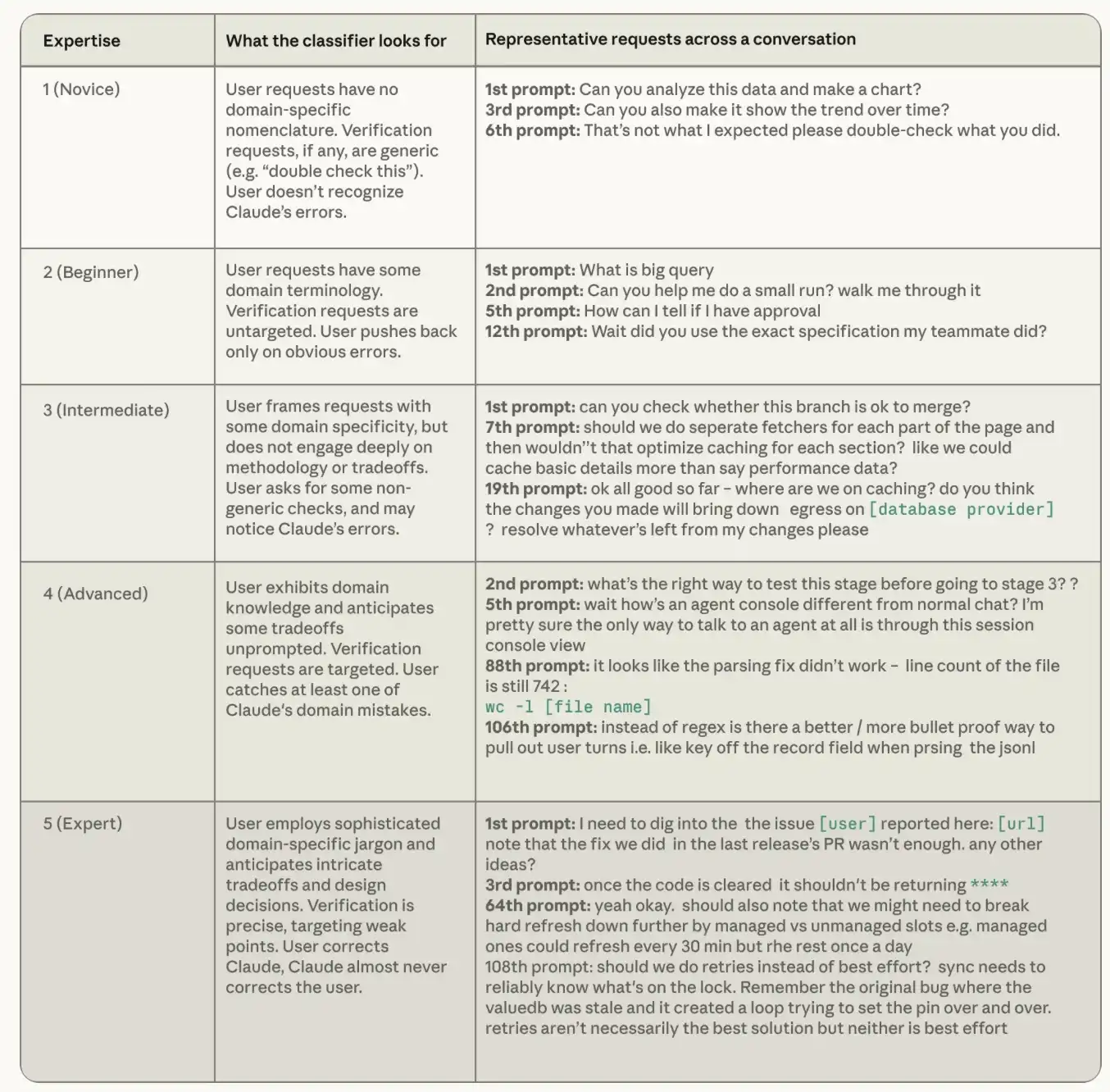
Table 1: Professional Level Classificationr. Example: Real sessions are rewrited, anonymously and compressed, and related sessions are marked by our sorters. Many of these examples come from open smart body programming session datasets SWE-chat。
We have quantified the relationship between the level of expertise and the output and activity generated by Claude's every hint. In typical start-up sessions, each hint triggers Claude to execute about five actions and output about 600 words; in specialist sessions, the action chain lengths more than twice the former, about 12 actions, while the output volume reaches about 3200 words, five times the former (see figure 3). This gap between newcomers and experts occurs within each type of work and each mission ' s value zone。
These indicators complement our previous study on the autonomy of Claude Code. Previous studies track the length of operation of intelligent bodies and the frequency with which users automatically approve their actions. By contrast, our decision-making indicators capture who's making substantive decisions throughout the session, while each hint triggers output and action, measuring the extent to which each human instruction triggers Claude's autonomous activity。
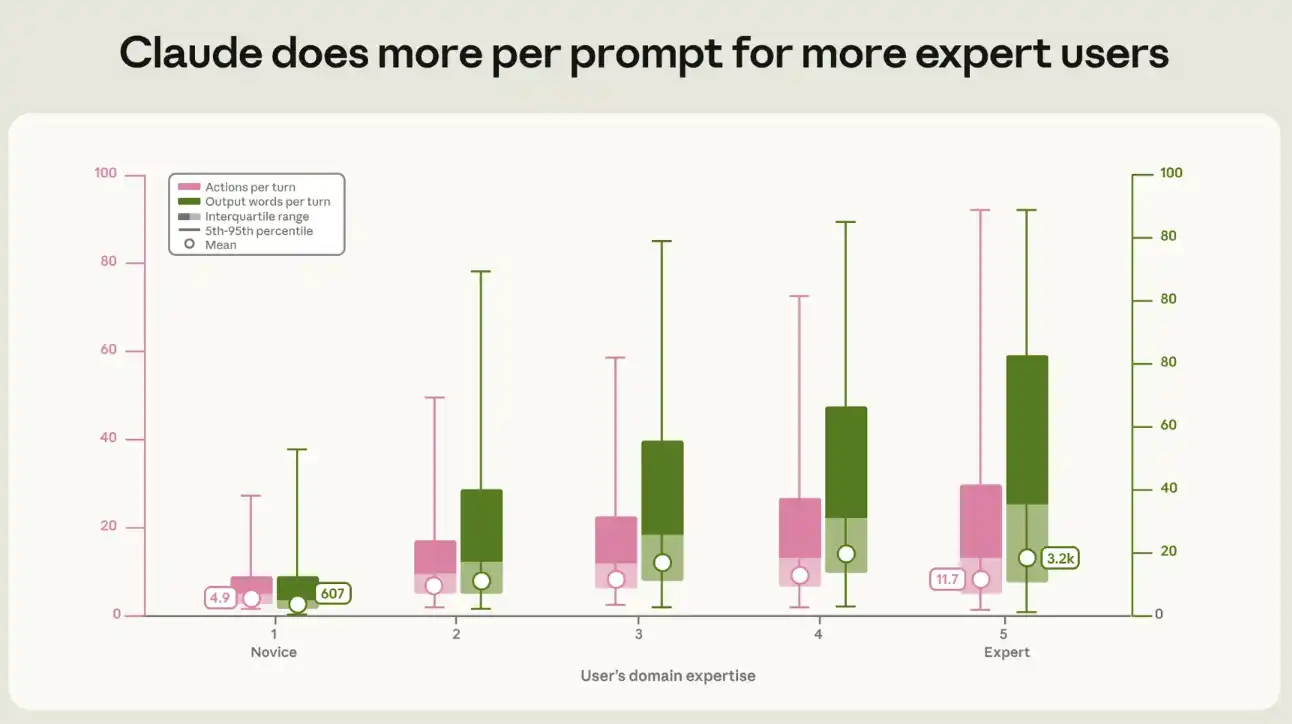
Figure 3: For more professional users, Claude has done more work per hint. The higher the level of professionalism, the more actions (left column) and text output (right column) are generated by Claude per hint. The box represents a quadrant and is divided in the medium range. Toggle indicates 5 to 95 percent. The white dot is geometric mean. Both upward trends are statistically significant (p & lt; 0.001) and the differences at each step between neighbouring professional levels are statistically significant. This trend remains significant after controlling work patterns, mission values, months, occupations and model series, and following errors by user group criteria: the number of actions increased by 9 per cent and the output increased by 13 per cent for each step of professional advancement。
Who's using Claude Code, and what are they doing with it
User
IN ORDER TO UNDERSTAND WHO IS DOING THIS, WE EXTRAPOLATE THE OCCUPATIONS OF EACH USER FROM THE SESSION LOG AND MAP THEM TO ONE OF THE 23 MAJOR CATEGORIES IN THE UNITED STATES BUREAU OF LABOR STATISTICS STANDARD CLASSIFICATION OF OCCUPATIONS (SOC). CATALOGUERS ARE REQUIRED TO JUDGE ONLY ON THE BASIS OF THE FOLLOWING SIGNALS: THE CONTEXT OF THE PROJECT, THE NAME AND STRUCTURE OF THE DOCUMENT, THE INFORMATION OR PRODUCT QUOTED BY THE USER AT THE BEGINNING OF THE SESSION, SUCH AS LEGAL DOCUMENTS, CLINICAL DATA, FINANCIAL REPORTS, COURSE MATERIALS, ETC., AND THE TERMINOLOGY USED BY THE USER. THE SORTER IS EXPLICITLY REQUIRED NOT TO CONSIDER "WRITING THE CODE" ITSELF AS EVIDENCE OF THE USER'S PROGRAMMING PROFESSION. ONLY IF THERE IS A CLEAR SIGNAL THAT THE SOFTWARE OR DATA WORK IS A USER'S OCCUPATION WILL THE SESSION BE CLASSIFIED AS A CODE-RELATED SOC CATEGORY, NAMELY, "COMPUTER AND MATH PROFESSION". IF A LAWYER CONSTRUCTS A SCRIPT FOR AUTOMATIC EXAMINATION OF THE ABSENCE OF CERTAIN TERMS IN A GROUP OF CONTRACTS, EVEN IF THE SESSION IS MAINLY ABOUT SOFTWARE, IT WILL BE PLACED IN THE LEGAL PROFESSION. IF THERE IS NO SIGNAL ABOUT THE USER PROFESSION, THE SESSION IS NOT CLASSIFIED。
We can extrapolate a career in about 70% of the sessions. It is not surprising that the “computer and mathematics profession” is the largest group in these classified sessions, as it covers most software-related work. The second is business and financial operations, art design and media, management, and life sciences, physical sciences and social sciences. In our sample, the fastest growing non-software occupational group is management, marketing and legal。
Work
From October 2025 to April 2026, there was a marked change in the composition of the work done using Claude Code. The most notable change was the decline in the proportion of sessions used to repair the damage code from 33 per cent to 19 per cent (see figure 4). Instead, more work around the code. The percentage of operating software rose from 14% to 21%. Writing and data analysis almost doubled, from about 10 percent to about 20 percent。
The value of the task itself is also on the rise. We approximate the economic value of each session by estimating the cost of the same type of work in the free-occupation market and calibrate it using real open job data sets. According to this indicator, the estimated value of the average session increased by 27 per cent between October and April. This increase occurred in various types of work. The value of the build, operate and repair categories increased by approximately 43 per cent, 34 per cent and 32 per cent, respectively. These price estimates are rough, so we use them primarily to compare trends over time between different missions rather than as direct readable dollar values. Details on how the mission value estimater was constructed are provided in the appendix。
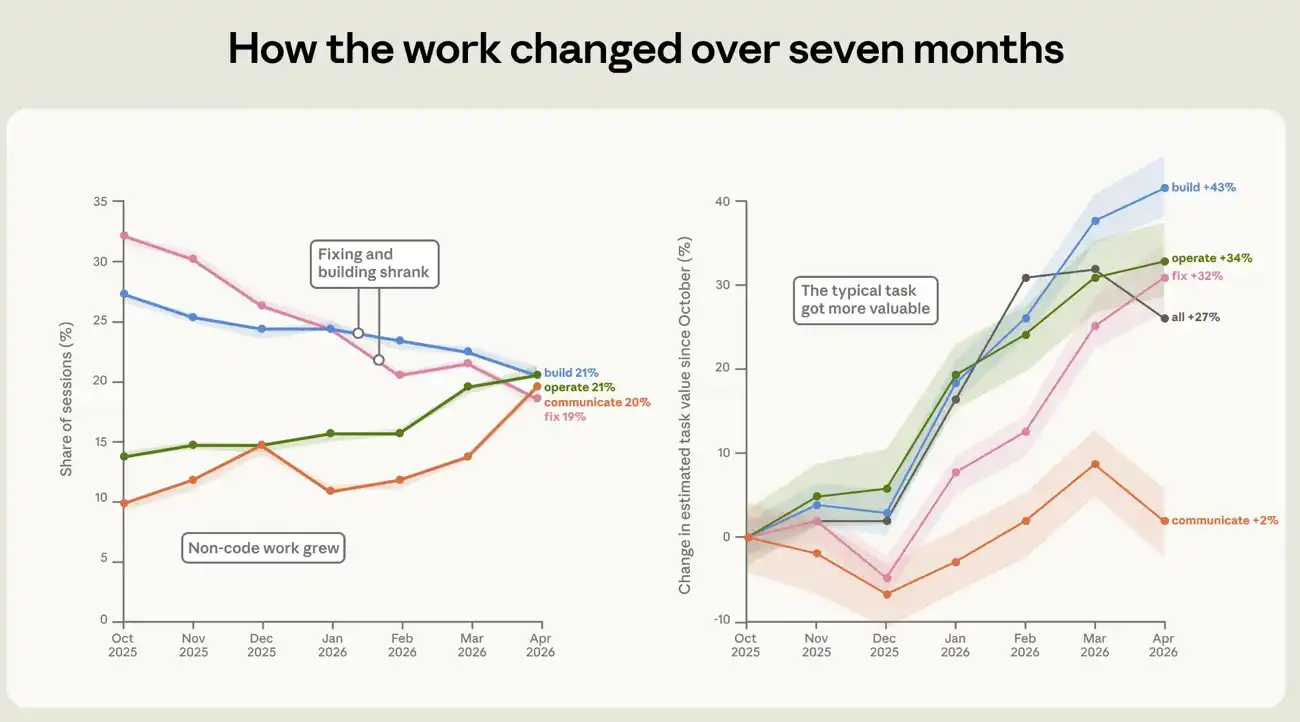
Figure 4: Changes in the composition and value of Claude Code ' s work from October 2025 to April 2026. The chart shows the proportion of work patterns in sessions over the seven-month window period. The proportion of sessions to repair damaged codes decreased from 33 per cent to 19 per cent, while the share of operating software, analytical data and document writing increased。
Success depends on what the user brings
Estimating the value of the task is one way to understand how Claude Code can help people do their job. Another perspective is to observe how many sessions have been successful and what characteristics of the sessions are relevant to success. Among all the indicators of success, we see a clear pattern: the higher the level of professionalism shown by users in the sessions, the greater the likelihood of success. Most of the upgrades are concentrated at the lower end of the profession, i.e., the gap between start-up and mid-level users is greater than the gap between mid-level and expert users。
Before analysing the characteristics of a successful session, we need to state precisely how success is measured. We can't observe the real world results of users, nor can we ask them directly whether they did what they wanted through Claude. We therefore rely on two complementary measurement methods, based on session records. The first is "success" , where users are judged by whether they have achieved their intended goals, including success, partial success, failure, and lack of clarity. Subsequently, the two accompanying cataloguers will assess the evidentiary strength of the judgement in order to determine “experimental success”. The successful signal classifier seeks verifiable evidence of success, including, in particular, guit activities that match the job, such as submission and pull requests, test package passage and explicit user approval. It scores the sessions according to the scale from "no signal" to "weak signal" (1 minute) to "multiplier hard signals" (5 minutes). Another parallel failure signal classifier rated evidence of errors, including errors, failed tests, repeated attempts at the same thing, and user objections to output. Both conditions are required for a proven success: the session is judged successful and there is at least one hard verifiable sign of success. The following analysis focuses on the degree of success or failure in the sessions, so we exclude those that have been identified by the successful outcome classifier as "undefined objectives " , which is approximately 7.7 per cent of the total sample。
Professional returns
So, which sessions are the easiest to succeed? The results show that the above-mentioned professional rating of the session has a significant impact on its success。
There may be concerns that professionalism is not the real driver. Perhaps the experts chose different mandates or there were differences in other areas. In this section, we partly respond to this concern by comparing the same type of work, the same estimated value, the same month, the same subject matter, and the conversation from the same broad occupational group, and look at how different professional levels of users can affect results。
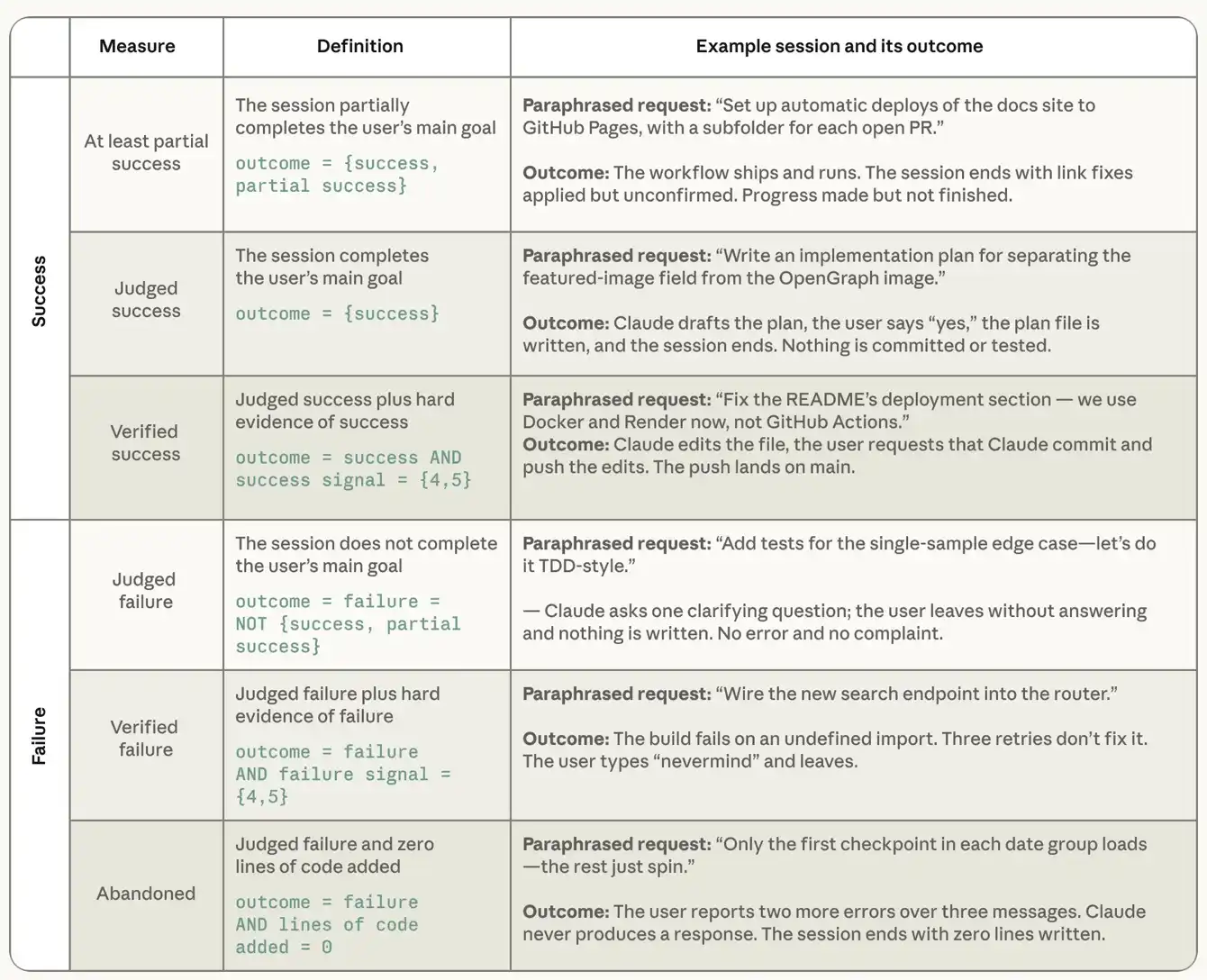
Table 2: Definition of success and failure derived from the classification. The example is from the real session in the open smart body programming interactive dataset SWE-chat, which is marked by our taxonomy after rewritten and summarized。
Of all the success indicators, the higher the level of professionalism demonstrated by users in the sessions, the more likely the sessions will be successful. The success rate for the newly rated session was 15 per cent for our strongest indicator of "experienced success", and 77 per cent for at least part of it. Meetings rated as mid-level and above were experienced from 28 to 33 per cent, with partial success ranging from 91 to 92 per cent (see figure 5)。
For each indicator, the majority of the gains are from the upgradation from the start to the middle; from the middle to the expert, the slopes slow. See appendix for details of the regression analysis behind figure 5。
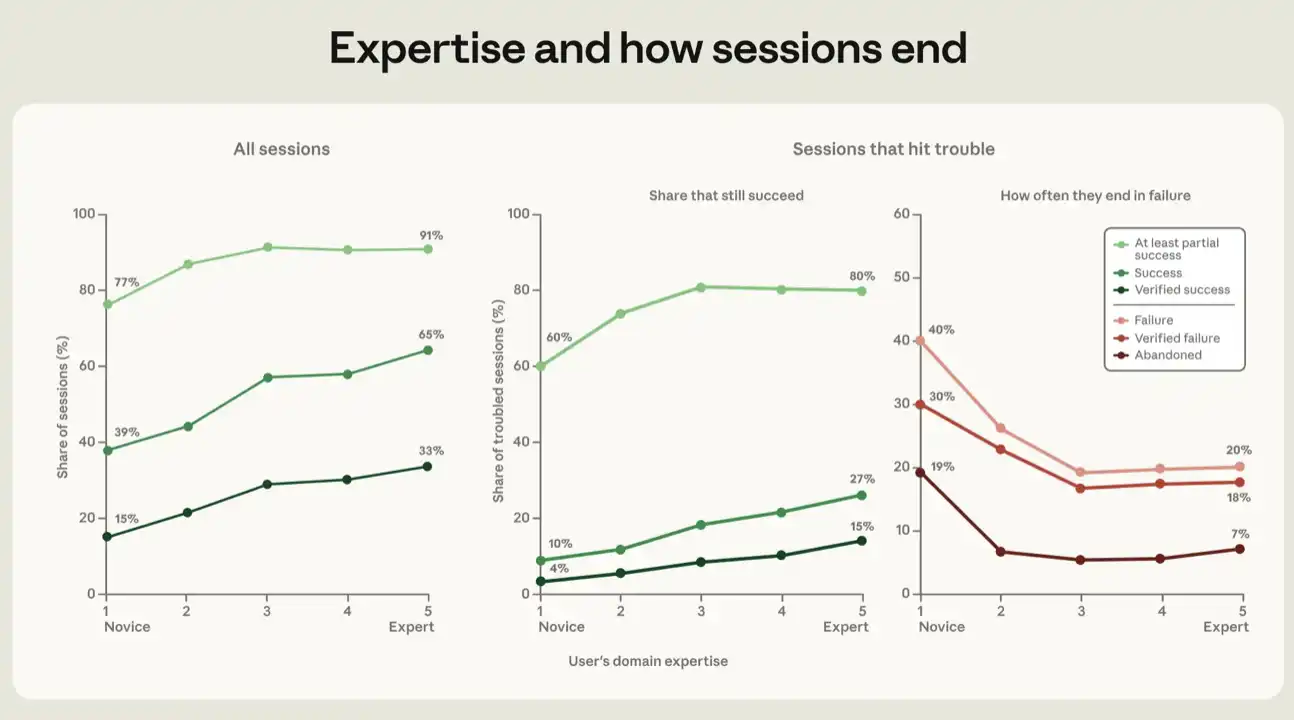
Figure 5: Results of professional participation. The chart shows the results of the session in five grades, from freshman to expert, according to the professional level of the user in the mission. Left chart contains all sessions. The center and right charts are limited to sessions where problems are encountered, i.e. where the signal of failure is greater than 3 and show how these sessions eventually reach different proportions of success and failure. Each point is the adjusted ratio. We estimate the differences between professional levels by comparing only sessions with the same working model, the same mission value range, the same month, the same mission theme, and the same user type, i.e., whether or not they belong to a software-related occupation. Details of the relevant returns are provided in the appendix. The wiring is the confidence zone of the sample average, most of which is invisible because of their smallness. These figures exclude sessions that have been identified by the successful outcome classifier as "undefined goals"。
A similar gradient can be observed in the challenged sessions. When the failure signal is recorded in empirical evidence of failure, we think the session is "problemed." This may include errors, test failures, multiple attempts to complete the same thing, or expressions of frustration and dissatisfaction by users. When all the above variables were controlled, the percentage of experienced success rose from 4 per cent of first-hand sessions to 15 per cent of expert sessions (see figure 5). If more liberal success indicators are used, we find at least a partial success rate of 60 per cent among start-up users and 80 to 81 per cent among mid-level to expert users。
We have also tracked another reverse relationship, the relationship between professionalism and various indicators of failure. It should be noted that, in this analysis, the sessions that have been convicted of failure are those that have not even been partially successful. If a session with a problem is judged to be a failure and is not written in any code line, we call it abandoned. Of the sessions where the user appears to be a rookie, 19% were eventually abandoned; in other user groups, the proportion was between 5% and 7%. In other words, users with the least experience are more likely to give up when they struggle to achieve their goals. Part of the value of professional competence appears to be the ability to direct intelligence back in the right direction。
Careers may be less important than professional qualifications
The empirical success rate for software-related occupational users in all sessions was about 30 per cent and for other occupational users about 26 per cent. In the generation session, where at least one line of code was added or modified, the figures were 34 per cent and 29 per cent, respectively (see figure 6). If a more liberal definition of success is used, the gap between software-related occupations and other occupations will be further narrowed. In the generation session, the two categories of users achieved at least partial success rates of 89 per cent and 88 per cent, respectively. The difference of five percentage points is not significant and has not widened or narrowed in seven months, although success rates have increased in both groups. In the generation session, each of the 10 largest occupational groups in our data set is within seven percentage points of success. Management-type occupations have the highest rates of proven success, slightly higher than software engineering-type occupations. Higher empirical success rates for managers may reflect the ability of management skills to migrate to the task of commanding intelligence. But this could be partly from our measurement: Validation relies to some extent on explicit confirmation by the users of the session, and managers may be more accustomed to expressing themselves when they get the results they want。
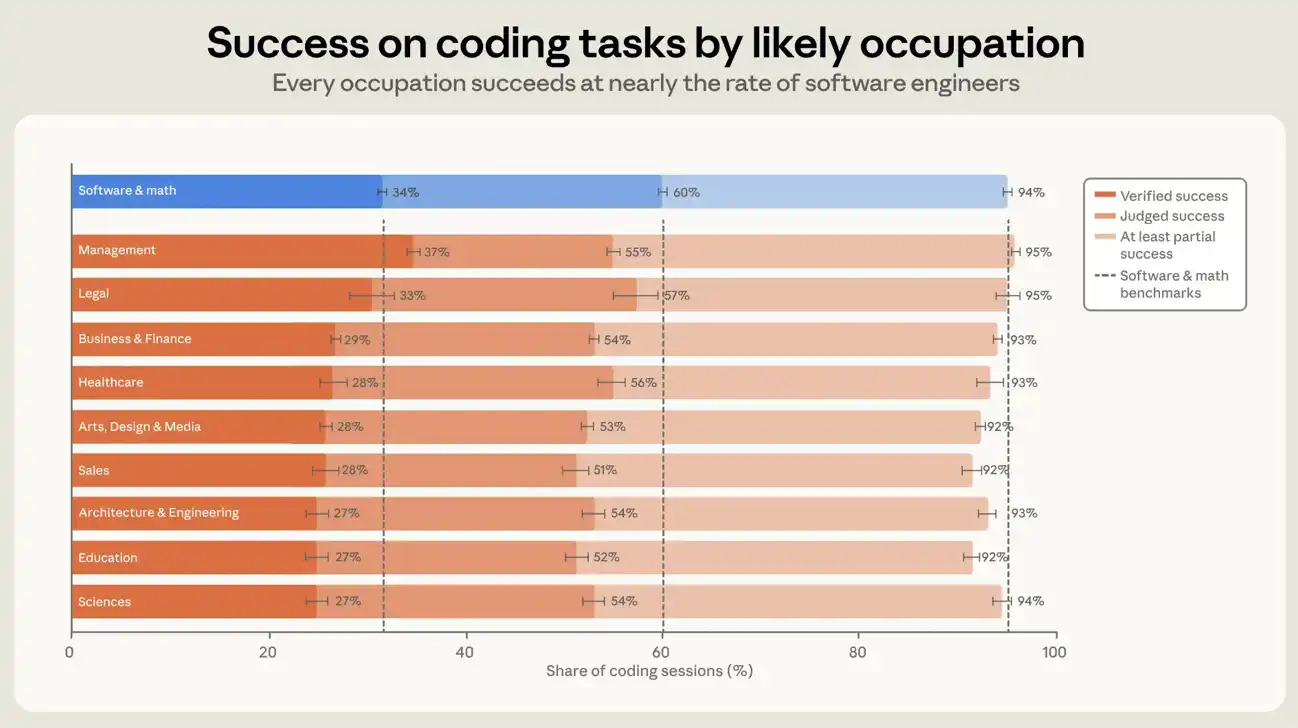
FIGURE 6: ENCODING SESSIONS BY INFER OCCUPATIONS DETERMINE SUCCESS RATES AND EMPIRICAL SUCCESS RATES. THE CHART SHOWS THE STRICT DEFINITION OF SUCCESS RATE BY USER EXTRAPOLATION OF OCCUPATIONAL CLASSIFICATION IN SESSIONS WHERE AT LEAST ONE LINE OF CODE HAS BEEN ADDED OR MODIFIED, INCLUDING SUCCESS DETERMINATION AND EXPERIENCE. THE FIGURE SHOWS THE 10 LARGEST OCCUPATIONAL GROUPS. THE DIFFERENCE IN SUCCESS RATES BETWEEN EACH GROUP AND SOFTWARE/MATHEMATICAL USERS, I.E. PROFESSIONAL USERS OF COMPUTERS AND MATHEMATICS IN SOC CLASSIFICATION, IS WITHIN SEVEN PERCENTAGE POINTS. THE ERROR LINE REPRESENTS 95 PER CENT CONFIDENCE INTERVAL BASED ON DIFFERENT ACCOUNTS。
Outlook
The results of this report outline an emerging picture: intelligent body programming is expanding some knowledge and skills while replacing others. The success rate of the major occupations in the generation sessions is not significantly different from the software-related occupations. It appears that coding intelligence is making programming background less important for successful programming。
At the same time, successful sessions are more likely to demonstrate field expertise. The expert session was rated as more than twice as successful as the newer session. When the session is problematic, the number of newcomers giving up is also several times higher than for other users. The collaborative approach itself makes this picture clearer: field experts can direct Claude to do more with each directive. Thus, the ability to lead Claude to success comes more from the ability to master an area than from the ability to write codes. It is now possible for anyone with such a mastery in any field to complete technical work that was previously impossible. Those who lack this professional understanding, i.e. use the same tools, will have much less to gain. Moreover, the benefits derive mainly from competence rather than excellence. With an operational understanding of a particular area, most of the benefits have already been achieved; on this basis, deep specialization will only provide a small additional advantage。
These findings are still preliminary. Like most of our studies, we cannot measure real world results, such as whether the code that was written in a session was subsequently used or discarded, or whether it produced economically valuable results. In addition, the non-interactive use excluded from this report represents a significant proportion of the overall activity. The development of a framework for measuring such use is one of the priorities for future work. Moreover, all categories of sessions depend on model reading of session records. In the appendix, we show that the sorter is consistent with the intended direction of the independent telemetry data and with the strong reference model judgement in most sessions. However, in a large-scale scenario, it remains difficult to verify the classification; Claude Code sessions themselves are more difficult because they may be too long and too complex to use manual labelling as a real benchmark。
As models, users and the division of labour between them evolve, the picture in the present report will also be continuously updated. We hope that these indicators will help us track the major transformations that are taking place. For example, if the returns from future professional levels begin to decline, this would indicate that the model is beginning to provide the critical judgement that users now bring and that the benefits of these tools will also be extended from field experts to a wider audience. If the proportion of successful coding sessions by users outside the software profession continues to rise, it may mean that software production is becoming part of the ordinary work in various fields rather than a product of a single occupation. These changes will change who can benefit from intelligent body programming, and how much they will benefit, and have an impact on the capacity that is most valued in the labour market。
[ Chuckles ]Original Link]
