
クロードコードを使用した方 回答はプログラマでない場合があります
プログラミングのしきい値が低下し、フィールド判定値の拡大をAIが下げた4千セッション

元のタイトル: 代理店の働き、輸出への現在のリターン
Anthropoicによる写真
ペギーによる写真
編集者: このレポートは、AIプログラミングツールが人とコードの関係を変えているかについて、約400,000のClaudeコードセッションに基づいています。
この記事の中央点は、インテリジェントなプログラミングでは、Claudeが主に「何をするか」を担当している間、人間は主に「何をするか」と決めています。 ユーザーは、Claudeがほとんどの実装を要する一方で、ほとんどの計画決定を下します。 つまり、AIはコードを書くこと、ドキュメントの変更、注文の実行、デバッグなどの達成を上回っていますが、ターゲティングと結果の判断は人に依存しています。
さらに重要なのは、Claudeコードを使用する効果は、ユーザーがプログラマであるかどうかだけに依存しません。 レポートは、法的な、財務、管理、科学などの非技術的な職業的ユーザーのコードの作成のタスクで、ソフトウェアエンジニアの近くにあります。 実際に結果に影響したのは、ユーザーが解決する問題を理解したかどうかでした。
つまり、AIプログラミングは、判断のしきい値ではなく、しきい値を下げることを意味します。 将来的には、ビジネスを知っている人、シーンを知る人、ニーズを分析し、結果を判断できる人は、単にコードを書く人よりもAIを使うことができるでしょう。 AIはフィールドに自動的に知識を交換しませんが、その価値を高めます。
以下は元のテキストです
主な調査結果
確立された研究に基づいて、私達は相互理性的なボディのプログラミングを勉強するためのフレームワークを提案しました。 枠組みは、10月2025日から4月2026日までの約400,000のクロードコードセッションのプライバシー保護分析に基づいており、ミッションの構成の評価、ヒトがAIとどのようにコラボレーションするか、ミッションの成功率に基づいています。
典型的なセッションでは、人間は最も計画的な決定に責任を負います。 クロードは、ほとんどの役員決定、すなわちそれを行う方法についての決定を担当しています。 与えられたフィールドでユーザーの ' s の専門知識が大きいほど、各命令が Claude を引き起こします。 コーディングの課題では、メインの職業グループの平均的な成功率 - つまり、ユーザーが何をしたいのか、テスト、提出コードなどの検証可能な証拠で、ソフトウェアエンジニアのほとんど同じです。
ユーザーの領域の専門知識が大きいほど、会話が正常に終わる可能性が高い。 しかし、中間ユーザーと専門家ユーザー間のギャップは重要ではありません。 7か月で、デバッグセッションの割合はほぼ半減し、使用モードはよりエンドツーエンドのスマートボディ使用量にシフトしました:展開と実行コード、データ分析、非コード文書の書き込み。
これら7ヶ月の間に、典型的なミッションの値はほぼすべてのジョブタイプでバラバラつきます。 無料のジョブで公開された情報と比較することで、ミッションの価値を推定し、1セントあたり約25の平均的な増加を示す。
導入事例
スマートボディプログラミングが急速に進んでいます。 2025年の終わり以来、GitHubのコーディングインテリジェンス活動の割合は2倍以上で、Claude Codeのユーザーは1週間の平均20時間でツールを使用します。 正式なプログラミングの経験を持つ人は、複雑な技術的なタスクを実行するためにインテリジェントなボディを正常に指示することはできませんか? これらのツールの急速な採用と能力強化は、より広範な知識作業にどのように影響しますか? 完全な回答を差し込むことはできませんが、Claude Code の初期信号をいくつか見ることができます。
このレポートは、Claude Code が実際に使用した方法についての証拠を提供します, 約のプライバシー保護分析に基づいて 235,000 ユーザーと約 400,000 対話セッション 10 月 2025 と 4 月 2026. Claudeコードの自律性指標に関する以前の研究とClaudeコードがAnthropicの内部作業をどのように変更したかを追記します。 この論文は、インタラクティブなAIプログラミングのアシスタントの使用を記述するためのフレームワークを提示します。 誰が何をするか、誰が成功するか。 コマンドラインインターフェイス(CLI)、Claude.ai、Claudeコードデスクトップアプリケーションを使用して、ユーザーがClaudeコードの使用を心配しています。 モデルの能力が成長するにつれて、スマートボディプログラミングの使用がどのように変化するかを追跡することで、プログラムの専門家や知識労働者の労働市場への影響をよりよく理解することができます。
クロードコードで何が起こるかは、知識作業の未来の兆候かもしれません。インテリジェントなボディは、非コーディングの仕事に徐々に埋め込まれています。 Claude は、より複雑で貴重なタスクを扱いました。 同時に、インテリジェントな身体のプログラミングに迷路の明確な分裂が残っています。人間は何を構築するかを決定し、インテリジェントな体が構築する方法を決定します。
また、プログラミングの能力ではなく、フィールドの専門知識によって実際のスケーリングアップツールが使用されるという証拠も見てきました。 特に、フィールドの専門家は間違いや誤解から成功し、回復する可能性が高いです。 しかし、専門家と中級のユーザー間のギャップは重要ではありません。 これは、特定の領域に十分な能力がある限り、このようなツールは、深さの専門家としてほぼ効果的に使用できることを示唆しています。
これらの調査結果は、労働市場の可能な変化の予備的な観察をすることができます。 私たちのデータでは、成功は、彼がまたは彼女がプログラミングで訓練されているかどうかではなく、自分が解決したい問題を理解しているかどうかによって異なります。 これらのモデルは、経済システム全体で確立されている場合は、スマートボディプログラミングツールは、現実化指向の作業の一部を吸収する可能性があるため、作業中に対処する問題を本当に理解している人にも報じます。 エンコーディングインテリジェンスは、代替分野に特化したものではありません。 逆に、より労働者は理性的な、より良質の仕事に理性的な実行できます持って来ます。
労働部門
クロードコードで何をしますか
Claude Codeの使い方を理解するために、各セッションを9つの作業モデルにグループ化し、セッションの目的を最もよく説明する単一の活動。 これらのモデルの4つは、コードの書き込みやメンテナンスに直接関連します。新しいものの構築、破損したものの修復、テストコードの修復、およびその他のインテリジェントまたは自動水ラインの配置。 他のカテゴリは、展開、構成、実行中のフローラインおよび監視システムを含む、オペレーティング・ソフトウェアです。 既存のシステムがどのように機能するかを理解し、変更を加える前に変更を計画するという2種類があります。 最後の2つのカテゴリは、コードに関連しない、またはコードは、最終製品の補助部品のみです。プレゼンテーションや他のテキストベースの文書によるデータと通信の分析。
コードライティング(25パーセント)、修理(26パーセント)またはテストおよび組織(5パーセント)で構成されたセッションの約56パーセント。 1セントあたり17、計画または探査のためのソフトウェアアカウントを操作します。 14パーセントと分析または13セントあたり書き込み (図1)を参照してください。
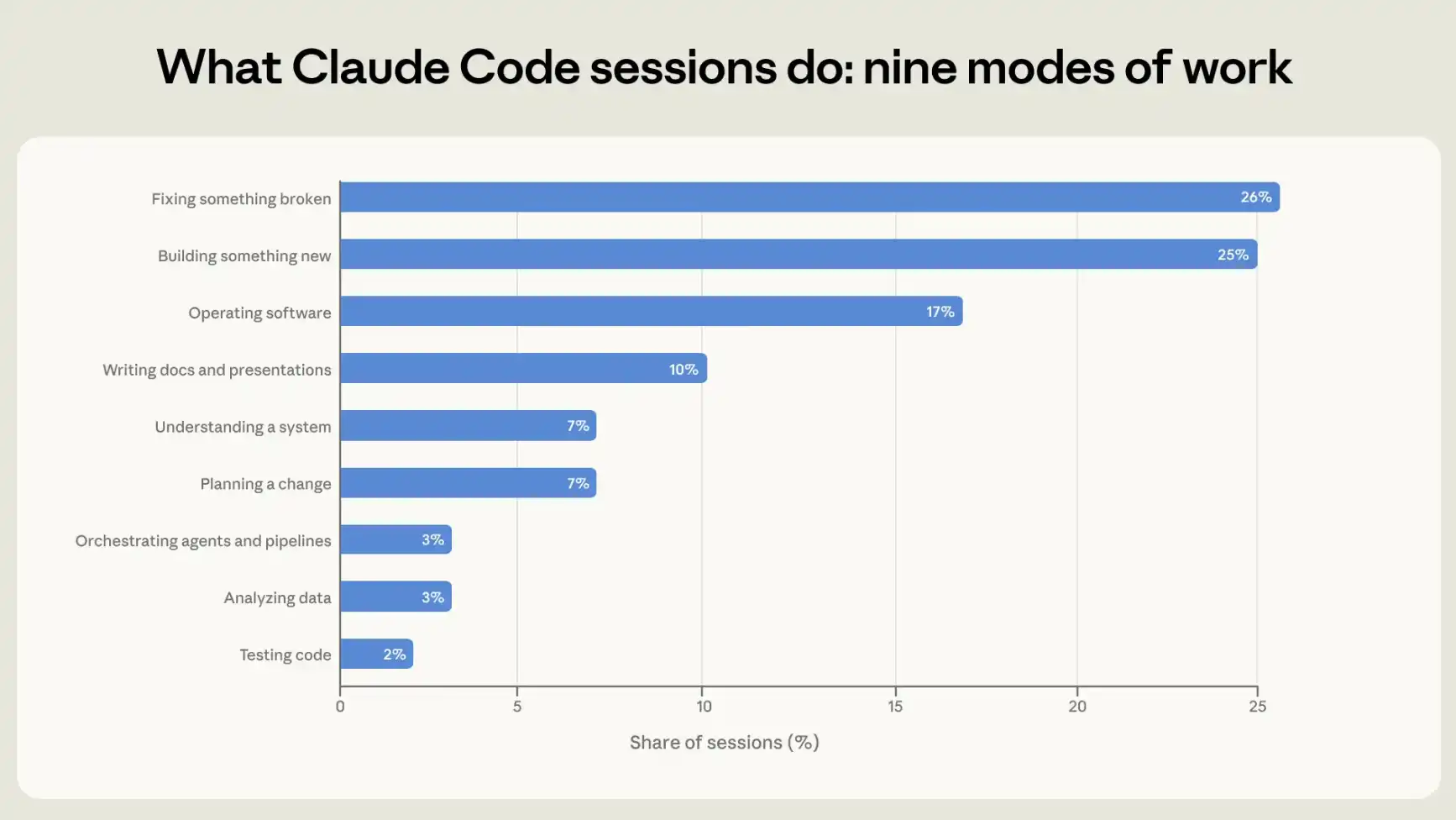
図1:9つの作業モデル。 各インタラクティブセッションは、その目的を最もよく説明する単一の作業モデルとして分類されます。
このモデルは、セッションレコードを読み、各セッションをそれに応じて分類することができます。その後、コードラインが追加または削除されたかどうかを含む、各セッションのために自動的に記録されたテレメトリーデータで分類結果をクロスチェックするために、当社のプライバシー保護分析ツールを使用します。 2つのソース間の一貫性の高度があります。 たとえば、私たちの課税がマークされているセッションの90%以上でコードを作成するか、または変更してもテレメトリーデータのコード変更が表示されます。 詳細は appendix を参照してください。
誰が決定をしますか
クロードコードはどのように強力ですか? 能力評価は、天井が高かったことを示し、まだ上昇していました。 たとえば、METR 時間の horizon の評価などのベンチマークテストでは、フロント ライン モデルは、数時間人間の努力を必要とし、プロセスの障害を克服するソフトウェア タスクを実行できるようになりました。 しかし、実際には、状況は何ですか? ここでは、各人がどれだけのガイダンスとクロードをしているかについて懸念しています。
2つの角度から見てみる まず、Claudeに対する決定を上回る人がいる程度を懸念しています。第二に、Claudeに割り当てられた行動の量を調べています。 セッションにおける意思決定の分裂を理解するため、セッションの内容に基づいてプライバシー保護の決定書を作成しました。 課税は、すべての意味のある決定をセッションにリストし、計画と実装の決定にそれらを分割するように依頼します。 計画決定には、何をすべきか、何をすべきか、何をすべきか、何をすべきかが含まれます。 実装の決定には、どの文書が変更されるか、どのコードが書かれているか、どの言語で、どの注文が操作されるかが含まれます。 続いて、カタログは、各決定をClaudeまたはユーザーに対して属性づけ、各セッションの2つの数値を生成します。ユーザーによる決定の割合と、ユーザーによる実装決定の割合。
平均して、人間は計画決定の約70パーセントを作るが、実施決定の1セントあたり20のみ(図2参照)。 実用的な使用では、インテリジェントなプログラミングは、労働の明確な分裂を形成します。人間は構築するべきことを決定し、インテリジェントな体は構築する方法を決定します。
セッションにおけるアクションの委任の程度を理解するためには、コンテンツではなく、セッションの構造で見ない。 Claude Code セッションは、Claude と user のラウンドアンドラウンドのインタラクションで構成されます。ユーザーはヒントを送信し、Claude はアクションを実行します。ユーザーは次のインタラクションを送信します。 典型的なセッションでは、そのような回転は約4つです。 10月から4月までの履歴データでは、ユーザーが送信したヒントは、Claudeを平均10アクションでトリガーし、100を超えることがあります。 各ラウンドでは、Claude はファイルを読み、コードを編集し、コマンドを実行し、平均 2400 語を出力します。
クラウドは、2人のユーザーチェックの間にどれだけの作業が決定を下しているかによって異なります。 ユーザーが実行プロセスの制御を保持する場合、すなわち、ユーザーが80%以上の執行決定を下すとき、Claudeは1ラウンドあたりのより少ないアクションを実行します。 そして、Claudeが計画の制御を取ったとき、Claudeは計画決定の80%以上を行なった、それは約16の行動の最高数を遂行しました。
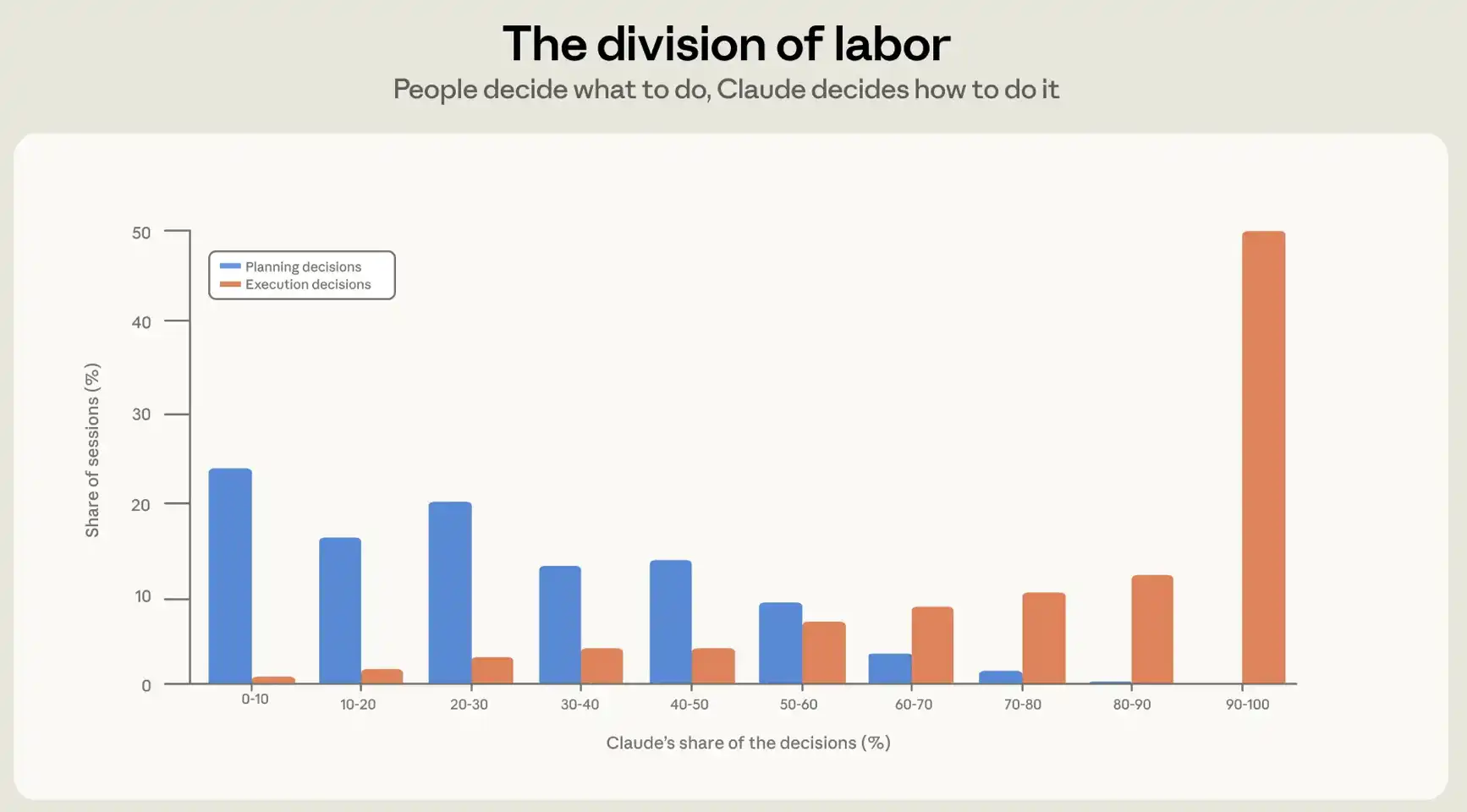
図2:Claude ' s の計画と意思決定の実装における共有。 数値は、異なるセッションで意思決定(何をすべきか)を計画し、実装の決定(それを行う方法)は、ユーザーの割合の分布ではなく、Claudeに帰属します。 典型的なセッションでは、Claudeが約80%の実装決定を下す一方で、ユーザーは約70%の計画決定を下します。
専門レベル
各セッションレコードによると、Claudeは、フレッシュマンからエキスパートまで、タスクでユーザーの明らかなプロフェッショナリズムを評価します。 プロのレベルの分類器は、3つの信号に焦点を当てています。ユーザーが指定した指示の正確さ、Claudeが何を検証するユーザーの要件、そしてユーザーがClaudeをもっと頻繁に修正するか、Claudeがより頻繁に確認するかどうか。 ここでプロフェッショナリズムのレベルがポストまたは一般的な能力の概念と完全に異なることに注意することが重要です。キーは、それがミッション固有のことです。 先輩のエンジニアがRustについて質問をしましたが、Rustのミッションでは初心者になるかもしれません。 Pythonを使用したことがない会計士は、Claude の調整規則が Python スクリプトに適用されなければならないのかを正確に伝えることができ、その月の最後に誤った処理された境界をキャプチャできるなら、このタスクの専門家です。
以下の表は、分類内のすべてのレベルでの専門性のレベルを定義し、オープンコード化されたスマートボディセッションデータセットSWE-chatから例を要求する方法を示しています。 「新しい手」と分類された対話は、特定の領域の知識を反映していない一般的な指示を与えます。 「専門家」と分類された対話は、コードライブラリと技術環境の深い理解を伝えます。
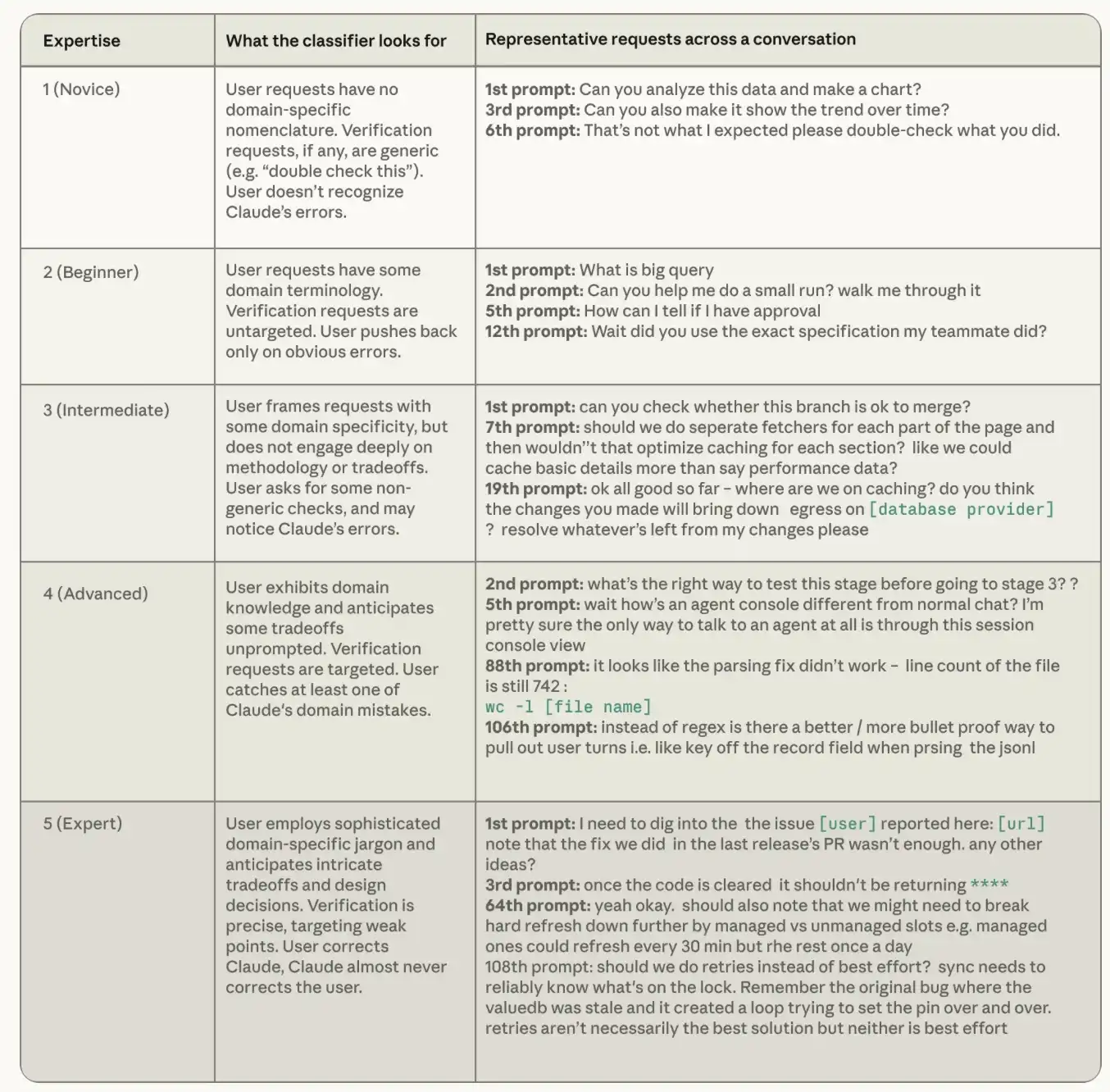
表1:専門レベルの分類器。 例: 実際のセッションはリライト、匿名で圧縮され、関連するセッションは、当社のソーダによってマークされます。 これらの例の多くは、オープンスマートボディプログラミングセッションデータセットSWE-chatから来ています。
私たちは、Claudeのあらゆるヒントによって生成された専門知識と出力と活動のレベルの関係を定量化しました。 典型的なスタートアップセッションでは、各ヒントはClaudeをトリガーし、約5つのアクションを実行し、約600語を出力します。 専門家のセッションでは、アクションチェーンは以前の2回以上、約12アクション、出力ボリュームは約3200語に達する一方で、前者5回(図3)を参照してください。 新規参入者と専門家同士のこのギャップは、各タイプの仕事と各ミッションの「sバリューゾーン」内で発生します。
これらの指標は、Claudeコードの自律性に関する以前の研究を補完します。 以前の研究では、インテリジェントな身体の動作の長さと、ユーザーが自動的にアクションを承認する頻度を追跡します。 対照的に、当社の意思決定指標は、セッション全体で実質的な決定を下している人をキャプチャし、各ヒントは出力とアクションをトリガーし、各人間の指示がクロードの自律的な活動を引き起こす範囲を測定します。
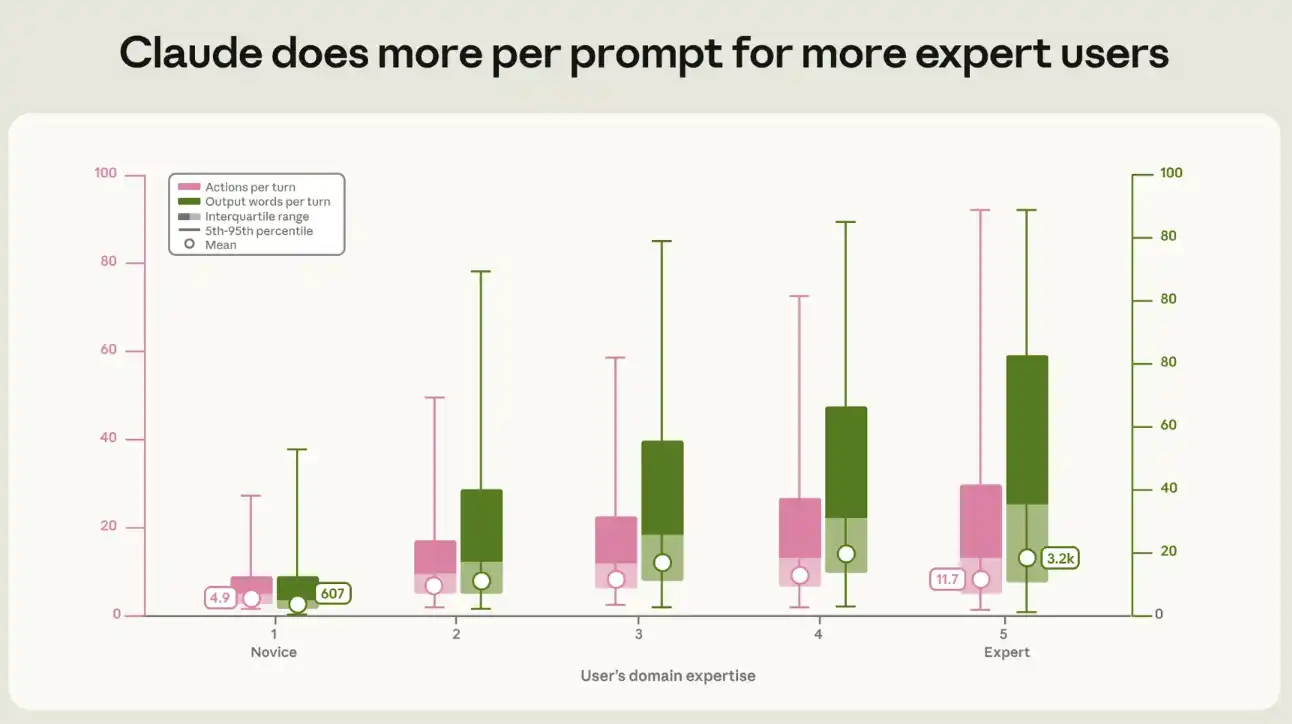
図3: よりプロフェッショナルなユーザーにとって、Claudeはヒントごとにより多くの仕事をしています。 プロフェッショナリズムのレベルが高いほど、複数のアクション(左列)とテキスト出力(右列)は、ヒントごとにClaudeによって生成されます。 箱は象限儀式を表し、媒体の範囲で分けられます。 トグルは5〜95パーセントを示す。 白い点は幾何学的な平均です。 上向きの傾向は統計的に有意である(p & lt;0.001)と隣接する専門レベル間の各ステップの違いは統計的に有意である。 この傾向は、作業パターン、ミッション値、月、職業、モデルシリーズの制御後、重要なままであり、ユーザーグループ基準によるエラーを次の:9セントで増加したアクションの数と、各ステップごとに13セントで出力が増加しました。
Claude Code を使っている人、Claude Code で何をしているの
ユーザー登録
これを行っている人を理解するために、セッションログから各ユーザーの占領を課し、米国労働統計局(SOC)の23の主要なカテゴリのいずれかにそれらをマップします。 以下の信号に基づいてのみを判断する必要があります。プロジェクトのコンテキスト、ドキュメントの名前と構造、法的文書、臨床データ、財務レポート、コース資料など、セッションの初めにユーザーが引用した情報または製品、およびユーザーが使用する用語。 ソーダは、「コードを書く」自体をユーザーのプログラミングの職業の証拠として考慮しないように明示的に要求されます。 ソフトウェアやデータワークがユーザーの職業であるという明確な信号がある場合にのみ、コード関連のSOCカテゴリ、すなわち「コンピュータと数学の職業」として分類されます。 弁護士が契約のグループで特定の条件の欠如の自動検査のためにスクリプトを構築した場合、セッションが主にソフトウェアについてであっても、法的な職業に置かれます。 ユーザの職業についての信号がない場合、セッションは分類されません。
セッションの約70%でキャリアを余儀なくすることができます。 「コンピューターと数学の職業」は、ほとんどのソフトウェア関連の作業をカバーするため、これらの分類されたセッションで最大のグループであることは驚くべきことではありません。 第二は、ビジネスと金融業務、アートデザイン、メディア、マネジメント、ライフサイエンス、物理科学、社会科学です。 当社のサンプルでは、最も急速に成長している非ソフトウェア職業グループは、管理、マーケティング、法的です。
業務内容
2025年10月~2026年4月には、クロードコードを使った作業の構成にマーク変更がありました。 最も注目すべき変更は、毎セント33から19までのダメージコードを修復するために使用されるセッションの割合の低下でした(図4)。 代わりに、コードの周りの作業が増えます。 14%から21%までの動作ソフトウェアの割合。 約10パーセントから約20パーセントまで、ほぼ2倍のデータ解析。
タスク自体の値は上昇にもなります。 各セッションの経済価値は、自由占有市場における同じタイプの作業のコストを推定し、実際のオープンジョブデータセットを使用してキャリブレーションします。 この指標によると、10月と4月の間に27セントで増加した平均セッションの推定値。 様々な仕事で増加しました。 1セントあたり約43、毎セント34、および毎セント32で増加したビルド、運用および修理カテゴリの値は、それぞれ。 これらの価格見積りは粗いので、直接読みやすいドルの値ではなく、異なるミッション間の傾向を比較するために主に使用します。 ミッション・バリュー・オフィサーがアレンディクスでどのように構築されたかの詳細。
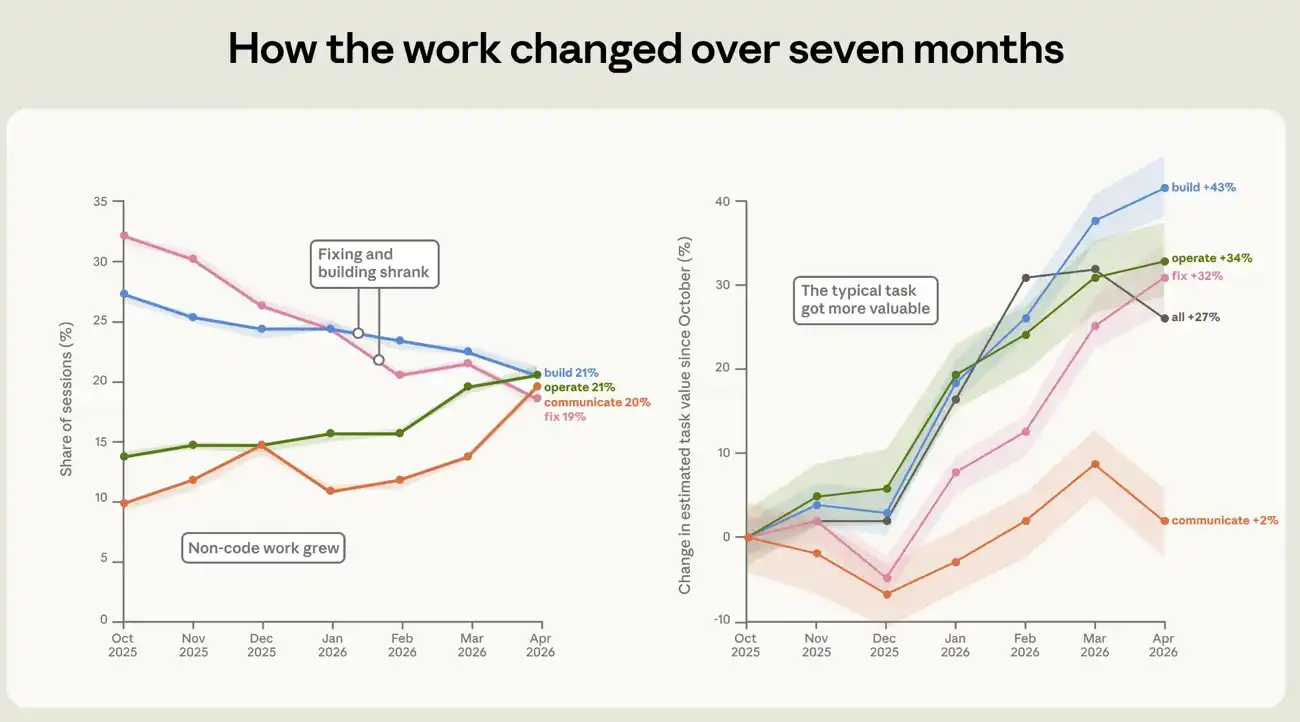
図4: 10月2025日から4月2026日までのClaude Code ' sの構成と値の変更。 グラフは、7ヶ月のウィンドウ期間にわたるセッションで作業パターンの割合を示しています。 破損したコードを修復するためのセッションの割合は、動作ソフトウェア、分析データ、文書の書き込みの共有が増加しながら、毎セント33から19に減少しました。
成功は、ユーザが何をもたらすかによって異なります
タスクの値を推定することは、Claude Code が人々が自分の仕事をするのに役立つ方法を理解する方法です。 別の視点は、セッションの成功と成功のどのような特徴が関係しているかを観察することです。 成功のすべての指標の中で、我々は明確なパターンを参照してください:セッションのユーザーによって示されるプロフェッショナリズムのレベルが高い、より大きな成功の可能性. アップグレードのほとんどは、職業の下の端に集中しています。つまり、スタートアップとミッドレベルのユーザー間のギャップは、中レベルのユーザーと専門家のユーザー間のギャップよりも大きいです。
成功したセッションの特徴を分析する前に、成功がどのように測定されるかを正確に把握する必要があります。 ユーザーの実際の結果は観察できません。また、Claudeを通じて望むものを直接質問することもできます。 したがって、セッションレコードに基づいて、2つの補完的な測定方法に依存しています。 まず「成功」であり、成功、部分的な成功、失敗、明快さの欠如など、ユーザーが意図した目標を達成したかどうかによって判断される。 続いて、同行する2人が「実験的な成功」を決定するために、判断の明らかな強さを評価します。 成功した信号の分類器は、投稿やプルリクエスト、テストパッケージの通過と明示的なユーザー承認など、ジョブに一致する、特に、ギット活動を含む、成功の検証可能な証拠を求める。 「信号なし」から「弱い信号」(1分)から「マルチプライヤーハード信号」(5分)までのスケールに応じてセッションをスコアリングします。 別の並列失敗信号の分類器は、エラー、失敗したテスト、同じことを繰り返した試み、および出力するユーザーの異議を含むエラーの証拠を評価しました。 両方の条件は、実績のある成功のために必要です。セッションは成功を判断し、成功の少なくとも1つの困難な検証可能な兆候があります。 次の分析は、セッションの成功または失敗の程度に焦点を当てています。したがって、成功した結果の分類器によって「未定義の目的」として識別されているものを排除します。これは、合計サンプルの1セントあたり約7.7です。
専門のリターン
それでは、成功する最も簡単なセッションは? 結果は、セッションの上記の専門格付けが成功に大きな影響を与えることを示しています。
プロフェッショナリズムが実際のドライバーではないという懸念があるかもしれません。 多分専門家は異なったmandatesを選んだか、他の区域に相違がありました。 このセクションでは、同じタイプの仕事、同じ推定値、同じ月、同じ主題、同じ広範な職業グループからの会話を比較し、ユーザーの異なる専門レベルが結果に影響を与えることができるかを見て、この懸念に部分的に対応します。
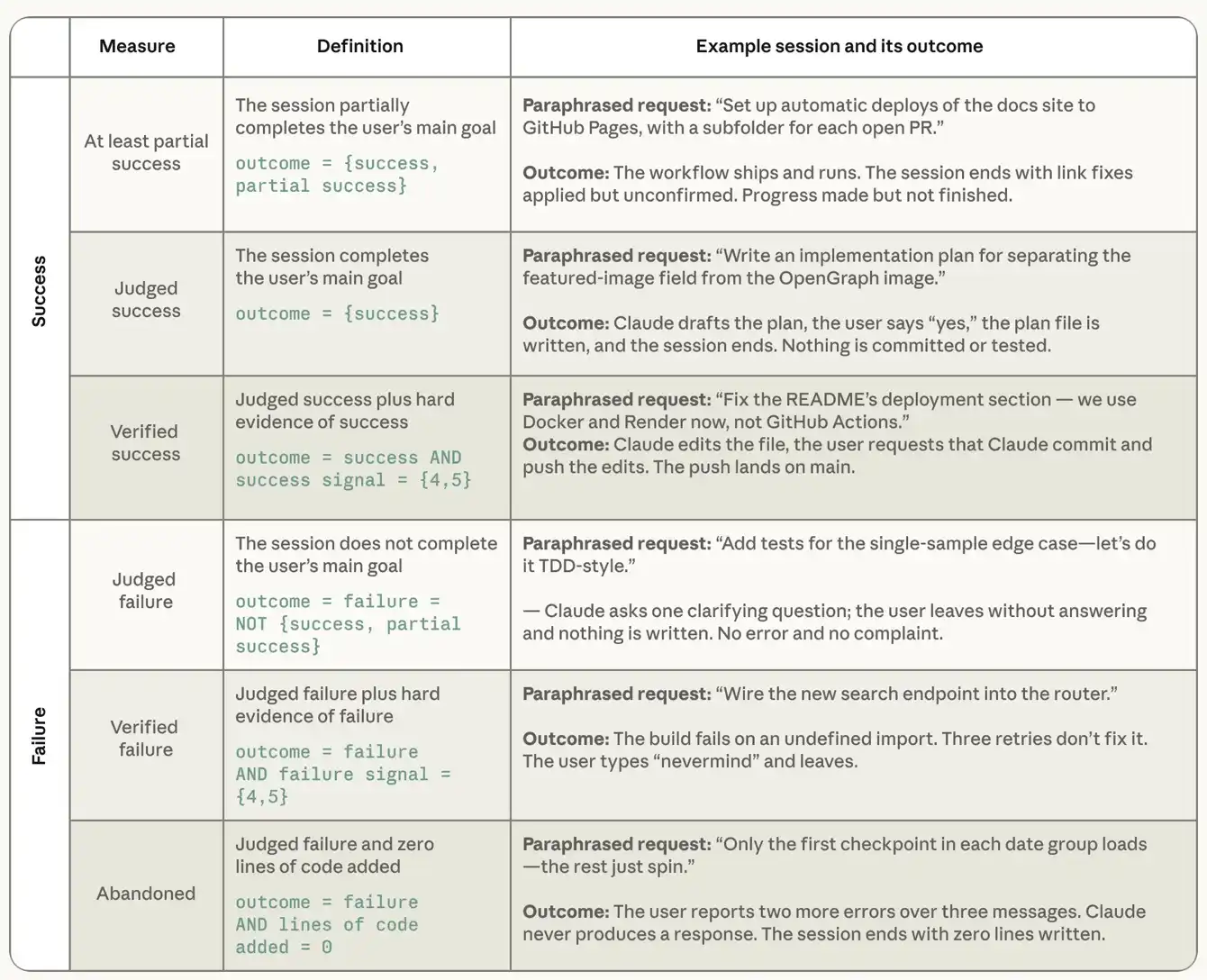
表2:分類から得られる成功と失敗の定義。 この例は、オープンなスマートボディプログラミングのインタラクティブなデータセットSWE-chatの実際のセッションから、書き換えと要約後に私たちの課税によってマークされます。
すべての成功指標のうち、セッションのユーザーによって実証されたプロフェッショナリズムのレベルが高いほど、セッションが成功する可能性が高くなります。 新しく評価されたセッションの成功率は、「経験豊かな成功」の最強指標で15パーセント、少なくとも1セントあたり77パーセントでした。 中間レベルと上記と評価された会議は28〜33セントで経験され、部分的な成功は91〜92セント(図5)の範囲です。
各指標では、ゲインの大部分は、スタートからミドルまでのアップグレードから、中央からエキスパートまで、ゲレンデは遅くなります。 図5の背後にある回帰解析の詳細については、付録を参照してください。
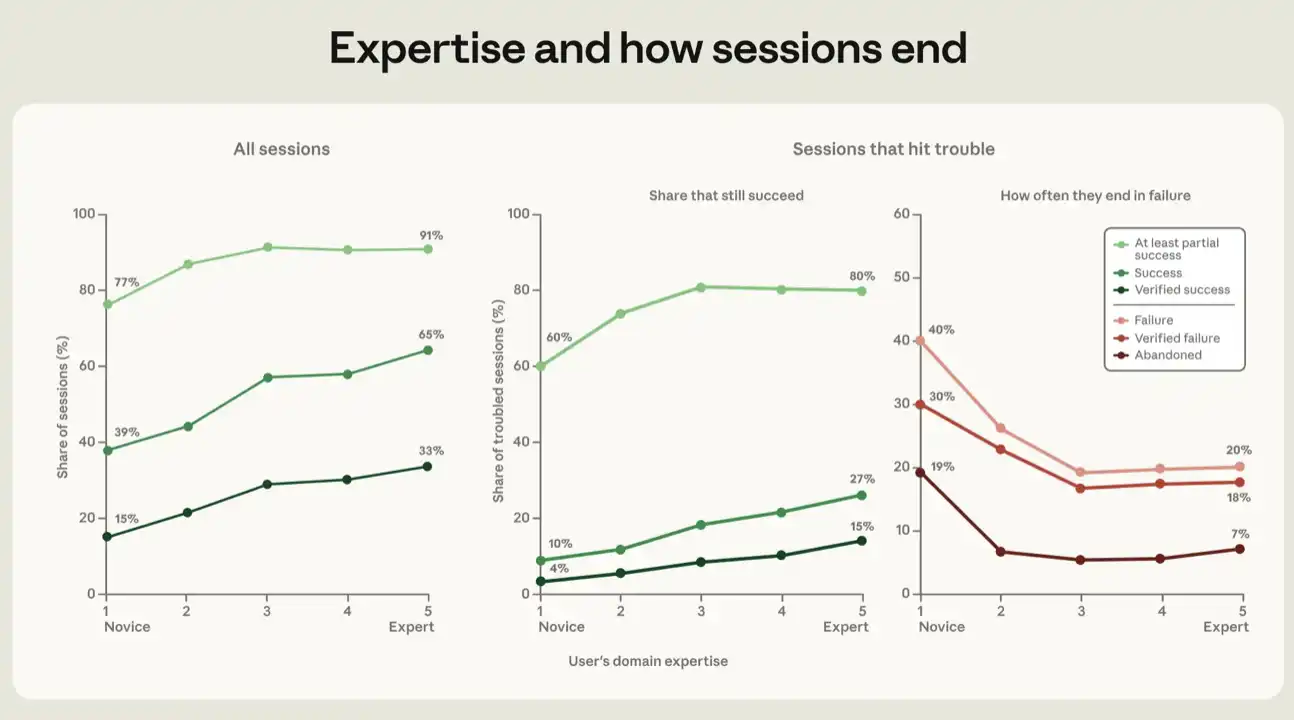
図5:専門家の参加の結果。 チャートは、ミッションのプロフェッショナルなレベルに応じて、フレッシュマンから専門家まで、5つのグレードのセッションの結果を示しています。 左チャートには全てのセッションが含まれています。 センターと右側のチャートは、問題が発生したセッションに限定されます。例えば、障害の信号が3よりも大きくなり、これらのセッションが最終的に成功と失敗の異なる比率に達する方法を示す。 各ポイントは調整比率です。 同じワーキング・モデル、同じミッション・バリュー・レンジ、同じ月、同じミッション・テーマ、同じユーザー・タイプ、すなわちソフトウェア関連の職業に属しているか否かを、専門レベルの違いを推定します。 関連するリターンの詳細は、付録に記載されています。 配線は、サンプル平均の自信ゾーンであり、そのほとんどは彼らの小さなさのために見えないものです。 これらの数字は、「未定義の目標」として成功した結果の分類器によって識別されたセッションを除く。
チャレンジセッションでは同様のグラデーションを観察することができます。 障害信号が故障の帝国証拠に記録されると、セッションは「問題」だと思う。 これは、エラー、テストの失敗、同じことを完了するための複数の試み、またはユーザーによる不満や不満の表現を含むことができます。 上記のすべての変数が制御されたとき、経験豊富な成功の割合は、専門家セッションの1セントから15パーセントまで上昇しました(図5)。 より審美的な成功指標が使用されている場合は、スタートアップユーザーと80〜81パーセントの60分の部分的な成功率を専門家のユーザーに見つけます。
我々はまた、別の逆の関係を追跡しました, プロフェッショムと故障の様々な指標の関係. この分析では、障害が起きたセッションは、部分的に成功していないことに注意する必要があります。 問題のあるセッションが失敗であると判断し、任意のコード行に記述されていない場合は、放棄します。 ユーザーがルーキーになるように見えるセッションのうち、19%は最終的に放棄されました。 他のユーザーグループでは、比率は5%〜7%でした。 言い換えると、少なくとも経験のあるユーザーは、自分の目標を達成するために苦労したときに諦める可能性が高いです。 プロフェッショナルな能力の部分は、正しい方向でインテリジェンスを指示する能力であるように見えます。
キャリアは、プロの資格よりも重要でない場合があります
すべてのセッションでソフトウェア関連の職業ユーザーのための帝国の成功率は、約30パーセントと約26パーセントの他の職業ユーザーのためにありました。 生成セッションでは、少なくとも1行のコードを追加または変更した場合には、それぞれ34パーセントと29セントの数字(図6)を参照してください。 成功のさらなる自由定義が使用される場合、ソフトウェア関連の職業と他の職業の間のギャップがさらに狭くなります。 世代別セッションでは、それぞれ1セントあたり89以上の部分的な成功率と88パーセントの2つのカテゴリを達成しました。 5つのパーセンテージポイントの差は重要ではなく、7ヶ月で幅が広く、または狭くなりますが、両方のグループで成功率が増加しています。 生成セッションでは、データセットの10の最大の職業グループが7パーセント以内に成功しています。 管理型職業は、ソフトウェアエンジニアリングタイプの職業よりも若干高い実績のある成功率を持っています。 管理者にとって高い執行率は、管理スキルの能力を反映し、コマンドインテリジェンスのタスクに移行することができます。 しかし、これは私たちの測定から一部である可能性があります: 検証は、セッションのユーザーによる明示的な確認のいくつかの範囲に依存し、マネージャーは、彼らが望む結果を得るとき、自分自身を表現するためにより慣れているかもしれません。
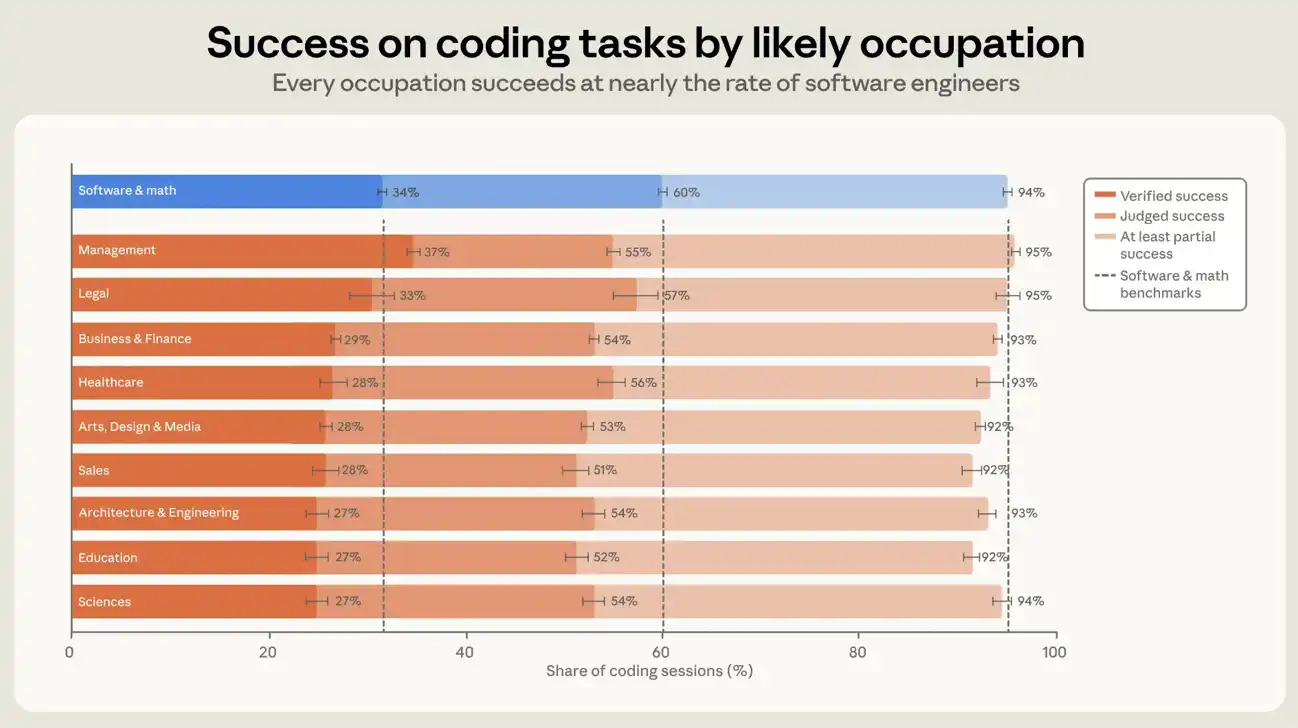
図6: 職業によるエンコーディングセッションは、成功率と永続的な成功率を決定します。 チャートは、成功の決定と経験を含む、少なくとも1行のコードを追加または修正されたセッションで職業分類のユーザーによる成功率の厳密な定義を示しています。 数字は10の最大の職業グループを示しています。 各グループとソフトウェア/数学ユーザー間の成功率の違い、すなわち、SOCの分類におけるコンピュータと数学の専門ユーザーの違いは、7パーセントポイント以内です。 エラー行は、異なるアカウントに基づいて、95パーセントの信頼区間を表します。
ニュース
このレポートの結果は、新しい画像: インテリジェントなボディプログラミングは、他の人を交換しながら、いくつかの知識とスキルを拡大しています。 世代セッションにおける主要な職業の成功率は、ソフトウェア関連の職業とは大きく異なります。 プログラミングを成功させるためには、プログラミングのバックグラウンドが重要でないということがわかります。
同時に, 成功したセッションは、フィールドの専門知識を実証する可能性が高い. 専門家のセッションは、新しいセッションとして2回以上成功を収めました。 セッションが問題となると、他のユーザーよりも数倍の新規参入者が増える。 共同アプローチ自体は、この画像をより明確にします。フィールドの専門家は、各ディレクティブでClaudeを指示することができます。 したがって、Claudeを成功に導く能力は、コードを書く能力よりも領域をマスターする能力から多く来ます。 これまで不可能だった技術作業を完成させるために、このようなマスタリーを得意とする人にとっては今は可能です。 この専門家の理解を欠いている人、すなわち同じツールを使用して、利益を得るためにはるかに少ないでしょう。 さらに、卓越性ではなく、主に有能から導かれる利点。 特定の領域の運用的理解により、ほとんどの利点は既に達成されています。 これにより、深い専門性はわずかな追加利点のみを提供します。
これらの調査結果はまだ暫定的です。 ほとんどの研究と同様に、セッションで書かれたコードがその後使用または廃棄されたか、経済的に価値のある結果を生み出すかなど、実際の結果を測定することはできません。 また、この報告書から除外された非対話的な使用は、全体的な活動の重要な比率を表します。 そのような使用を測定するためのフレームワークの開発は、将来の仕事の優先事項の一つです。 また、全てのセッションは、セッションレコードのモデル読み込みに依存します。 付録では、選別機は独立したテレメトリーデータの意図された方向と、ほとんどのセッションで強い参照モデル判断で一貫していることを示しています。 しかし、大規模なシナリオでは、分類を検証するのは難しいままです。 クロード コード セッション自体はより困難です。なぜなら、マニュアル ラベリングを実際のベンチマークとして使用するために長すぎて複雑すぎる可能性があるからです。
モデル、ユーザー、およびそれらの間の労働の分裂が進化するにつれて、現在の報告書の画像も継続的に更新されます。 これらの指標は、私たちが取っている主要な変化を追跡するのに役立つことを願っています。 たとえば、将来の専門レベルからのリターンが低下し始めると、このモデルは、ユーザーが今持って来る重要な判断を提供し始め、これらのツールの利点は、フィールドの専門家からより広い聴衆に拡張されることを示しています。 ソフトウェアの専門職以外のユーザーによる成功したコーディングセッションの割合が上昇し続ける場合、ソフトウェアの生産は単一の職業の製品ではなく、さまざまな分野における通常の作業の一部になっていることを意味するかもしれません。 これらの変更は、インテリジェントなボディプログラミングの恩恵を受けることができる人と、彼らがどれだけ利益をもたらすかを変更し、労働市場で最も評価される能力に影響を与えます。
[ チャック ]オリジナルリンク]
